Kaggle Titanic データで学ぶ、基本的な可視化手法
はじめに
【随時更新】Kaggle テーブルデータコンペで使う EDA・特徴量エンジニアリングのスニペット集におけるスニペットを主に利用して、 Kaggle の Titanic データ を利用して基本的なデータの可視化を行います。
前提
import numpy as np import pandas as pd import pandas_profiling as pdp import matplotlib.pyplot as plt import seaborn as sns import warnings warnings.filterwarnings('ignore') cmap = plt.get_cmap("tab10") plt.style.use('fivethirtyeight') %matplotlib inline pd.set_option('display.max_rows', None) pd.set_option('display.max_columns', None) pd.set_option("display.max_colwidth", 10000)
target_col = "Survived" data_dir = "/kaggle/input/titanic/"
フォルダの確認
!ls -GFlash /kaggle/input/titanic/
total 100K 4.0K drwxr-xr-x 2 nobody 4.0K Jan 7 2020 ./ 4.0K drwxr-xr-x 5 root 4.0K Jul 12 00:15 ../ 4.0K -rw-r--r-- 1 nobody 3.2K Jan 7 2020 gender_submission.csv 28K -rw-r--r-- 1 nobody 28K Jan 7 2020 test.csv 60K -rw-r--r-- 1 nobody 60K Jan 7 2020 train.csv
データを読みこむ
train = pd.read_csv(data_dir + "train.csv") test = pd.read_csv(data_dir + "test.csv") submit = pd.read_csv(data_dir + "gender_submission.csv")
データを確認
train.head()

レコード数、カラム数の確認
print("{} rows and {} features in train set".format(train.shape[0], train.shape[1])) print("{} rows and {} features in test set".format(test.shape[0], test.shape[1])) print("{} rows and {} features in submit set".format(submit.shape[0], submit.shape[1]))
891 rows and 12 features in train set 418 rows and 11 features in test set 418 rows and 2 features in submit set
カラムごとの欠損数を確認
カラムごとにどのくらい欠損があるか確認する。
train.isnull().sum()
PassengerId 0 Survived 0 Pclass 0 Name 0 Sex 0 Age 177 SibSp 0 Parch 0 Ticket 0 Fare 0 Cabin 687 Embarked 2 dtype: int64
欠損値の可視化
欠損に規則性があるか確認する。
plt.figure(figsize=(18,9)) sns.heatmap(train.isnull(), cbar=False)

各カラムの要約統計量の確認
各カラムごとに平均や標準偏差、最大値、最小値、最頻値などの要約統計量を確認してデータをざっと理解する。
train.describe()

データの件数 (頻度) を集計
ターゲットの割合を確認
sns.countplot(x=target_col, data=train)

カテゴリ値の割合を確認
col = "Pclass" sns.countplot(x=col, data=train)

ターゲットの値ごとのあるカラムの割合を確認
col = "Pclass"
sns.countplot(x=col, hue=target_col, data=train)

col = "Sex"
sns.countplot(x=col, hue=target_col, data=train)

ヒストグラム
縦軸は度数、横軸は階級で、データの分布状況を可視化する。 ビンの大きさが異なれば異なったデータの特徴を示すためいくつか試す。
col = "Age" train[col].plot(kind="hist", bins=10, title='Distribution of {}'.format(col))

col = "Fare" train[col].plot(kind="hist", bins=50, title='Distribution of {}'.format(col))

カテゴリごとのヒストグラム
f, ax = plt.subplots(1, 3, figsize=(15, 4)) sns.distplot(train[train['Pclass']==1]["Fare"], ax=ax[0]) ax[0].set_title('Fares in Pclass 1') sns.distplot(train[train['Pclass']==2]["Fare"], ax=ax[1]) ax[1].set_title('Fares in Pclass 2') sns.distplot(train[train['Pclass']==3]["Fare"], ax=ax[2]) ax[2].set_title('Fares in Pclass 3') plt.show()

ターゲットのカテゴリごとのカラムのヒストグラム
col = "Age" fig, ax = plt.subplots(1, 2, figsize=(15, 6)) train[train[target_col]==1][col].plot(kind="hist", bins=50, title='{} - {} 1'.format(col, target_col), color=cmap(0), ax=ax[0]) train[train[target_col]==0][col].plot(kind="hist", bins=50, title='{} - {} 0'.format(col, target_col), color=cmap(1), ax=ax[1]) plt.show()

ターゲットの値ごとのあるカラムのヒストグラム(重ねる場合)
col = "Age" train[train[target_col]==1][col].plot(kind="hist", bins=50, alpha=0.3, color=cmap(0)) train[train[target_col]==0][col].plot(kind="hist", bins=50, alpha=0.3, color=cmap(1)) plt.title("histgram for {}".format(col)) plt.xlabel(col) plt.show()

カーネル密度推定
ざっくりいうとヒストグラムを曲線化したもの。Xに対するYを取得できる。
sns.kdeplot(label="Age", data=train["Age"], shade=True)

クロス集計
カテゴリデータのカテゴリごとの出現回数を算出する。
pd.crosstab(train["Sex"], train["Pclass"])

pd.crosstab([train["Sex"], train["Survived"]], train["Pclass"])

ピボットテーブル
カテゴリごとの量的データの平均
pd.pivot_table(index="Pclass", columns="Sex", data=train[["Age", "Fare", "Survived", "Pclass", "Sex"]])

カテゴリごとの量的データの最小値
pd.pivot_table(index="Pclass", columns="Sex", data=train[["Age", "Fare", "Pclass", "Sex"]], aggfunc=np.min)

散布図
2つのカラムの関係性を確認する。
散布図
sns.scatterplot(x="Age", y="Fare", data=train)

散布図(カテゴリごとに色分け)
sns.scatterplot(x="Age", y="Fare", hue=target_col, data=train)

散布図行列
sns.pairplot(data=train[["Fare", "Survived", "Age", "Pclass"]], hue="Survived", dropna=True)

箱ひげ図
データのばらつきを視覚化する。
カテゴリごとの箱ひげ図
カテゴリごとにデータのばらつきを確認する。
sns.boxplot(x='Pclass', y='Age', data=train)

ストリップチャート
データをドットで表した図。2つのデータに一方がカテゴリカルな場合に利用する。
sns.stripplot(x="Survived", y="Fare", data=train)

sns.stripplot(x='Pclass', y='Age', data=train)

ヒートマップ
カラムごとの相関係数のヒートマップ
sns.heatmap(train.corr(), annot=True)

参考
JupyterLab で Jupyter notebook(ipynb)の 差分を見やすく Git管理する
TL;DR

Jupyter Notebook で分析を進める際、バージョン管理をしたいと思いGitで管理をしてみましたが、普通に進めるとNotebook のメタデータによって差分がとても見づらかったので、JupyterLab の jupyterlab-gitと nbdimeエクステンションを利用し、差分を見やすく表示できるようにしてみました。
JupyterLab 環境を構築
今回の記事では、下記の環境を利用します。
- docker-compose を使用
- docker-compose のインストールは こちら を参照
- コンテナイメージのベースは kaggle-images を利用
Jupyter notebook のバージョンコントロールに必要な JupyterLab エクステンションは下記になります。
- jupyterlab-git
- nbdime
- こちらは jupyterlab-git をインストールすると一緒にインストールされる
環境構築
下記2ファイルを作成します。
- Dockerfile
FROM gcr.io/kaggle-images/python:v74 RUN apt-get update && \ apt-get install -y git \ curl RUN curl -sL https://deb.nodesource.com/setup_12.x | bash - &&\ apt-get install -y nodejs RUN pip install -U pip \ jupyterlab && \ pip install jupyterlab-git RUN jupyter lab build
- docker-compose.yml
version: "3" services: jupyter: build: . volumes: - $PWD:/tmp/work working_dir: /tmp/work ports: - 8888:8888 command: jupyter lab --ip=0.0.0.0 --allow-root --no-browser
Docker イメージのビルド
上記2ファイルを作成後、同ディレクトリにてビルドします。
$ docker-compose build
コンテナを起動
ビルド後コンテナを起動します。
$ docker-compose up
起動後は http://localhost:8888/ にアクセスし、token を入力して JupyterLab にアクセスできます。
token とは起動後に出力される、例:http://acb729d0c5ce:8888/?token=45d10c660d2e85f0c8d59995a04667c154542ae79f27f65d の 45d10c660d2e85f0c8d59995a04667c154542ae79f27f65d にあたる箇所です。
Extension Manager を Enable
起動後は Exxtension Manager を Enable します。
 2つのエクステンションがインストールされています。
2つのエクステンションがインストールされています。

Notebook を Git でバージョン管理をする
Git リポジトリ を Clone
必要なリポジトリをクローンします。すでに Notebook などがある場合は git init などをします。

リポジトリの URL を入力

Notebook (test.ipynb) を作成して first commit します。
$ git config --global user.email "you@example.com" $ git config --global user.name "Your Name" $ git add test.ipynb $ git commit -m "first commit"
first commit 後、 Notebook で分析を進めたとします。例えば df.head() というコードを追加したとします。
git diff での差分表示
まず、git diff コマンドで確認した場合は、下記のように Notebook のメタデータなどの差分が表示されてしまいとてもわかりづらいです。
# git diff
diff --git a/test.ipynb b/test.ipynb
index f6c1f17..5af6074 100644
--- a/test.ipynb
+++ b/test.ipynb
@@ -2,7 +2,7 @@
"cells": [
{
"cell_type": "code",
- "execution_count": 1,
+ "execution_count": 6,
"metadata": {},
"outputs": [],
"source": [
@@ -21,7 +21,7 @@
},
{
"cell_type": "code",
- "execution_count": 4,
+ "execution_count": 7,
"metadata": {},
"outputs": [],
"source": [
@@ -30,12 +30,164 @@
},
{
"cell_type": "code",
- "execution_count": 5,
+ "execution_count": 8,
"metadata": {},
"outputs": [],
"source": [
"df = pd.read_csv(data_dir + \"train.csv\")"
]
+ },
+ {
+ "cell_type": "code",
:
JupyterLab nbdime での差分表示
JupyterLab にて nbdime を利用して diff を確認した場合は下記になります。ピンクの左側は変更前、緑の右側は変更後になります。

とても見やすく差分が表示されていると思います。
参考
コマンドラインで AtCoder のテストケース取得、テスト、提出までを行う
はじめに
atcoder-cli, online-judge-tools でターミナル上 (Mac) でテストケース取得、テスト、提出まで行う手順です。
事前準備
必要なツールのインストール
$ pip3 install online-judge-tools
$ npm install -g atcoder-cli
$ pip3 install selenium
ツールで AtCoder へログイン
$ acc login $ oj login https://atcoder.jp/
設定
全部の問題ディレクトリが作られるようにする。例えば、AtCoder Begginer Contest の場合、acc new abcXXX コマンドで a ~ f の問題が作成されるようにする
$ acc config default-task-choice all
config ディレクトリの場所を表示
$ acc config-dir
テンプレート設定を行う。config ディレクトリに template 名のフォルダを作成し、その中にテンプレートのソースコード (例:main.py)と、テンプレートの設定ファイル(template.json)を作成する。
# config ディレクトリへ移動 $ cd /Users/xxxxxxxxxx/Library/Preferences/atcoder-cli-nodejs $ mkdir py $ cd py $ touch main.py template.json # 問題のディレクトリを作った時に、main.py が作成され、提出対象も main.py とする $ vim template.json $ cat template.json { "task":{ "program": ["main.py"], "submit": "main.py" } } # main.py が作成された時のデフォルト設定を編集する。 # `#!/usr/bin/env python3` は必要。自分の場合はよくある入力パターンをデフォルトで書き込んでいる。 $ vim main.py $ cat main.py #!/usr/bin/env python3 S = input() N = int(input()) S = input().split() A, B, C = input().split() L = list(map(int, input().split())) H, N = map(int, input().split()) # デフォルトのテンプレートの設定を py にする (py ディレクトリで設定したファイルが適用) $ acc config default-template py # テンプレートの確認 $ acc templates search template directories in /Users/xxxxxxxxxx/Library/Preferences/atcoder-cli-nodejs NAME SUBMIT-PROGRAM py main.py
ディレクトリ作成
下記の例は、AtCoder Bergginer Contest 154 のディレクトリを作成する場合。main.py とテストの入力と出力のファイルが作成される。
$ acc new abc154
$ tree
.
├── a
│ ├── main.py
│ └── tests
│ ├── sample-1.in
│ ├── sample-1.out
│ ├── sample-2.in
│ └── sample-2.out
├── b
│ ├── main.py
│ └── tests
│ ├── sample-1.in
│ ├── sample-1.out
│ ├── sample-2.in
│ ├── sample-2.out
│ ├── sample-3.in
│ └── sample-3.out
├── c
│ ├── main.py
│ └── tests
│ ├── sample-1.in
│ ├── sample-1.out
│ ├── sample-2.in
│ ├── sample-2.out
│ ├── sample-3.in
│ └── sample-3.out
├── contest.acc.json
├── d
│ ├── main.py
│ └── tests
│ ├── sample-1.in
│ ├── sample-1.out
│ ├── sample-2.in
│ ├── sample-2.out
│ ├── sample-3.in
│ └── sample-3.out
├── e
│ ├── main.py
│ └── tests
│ ├── sample-1.in
│ ├── sample-1.out
│ ├── sample-2.in
│ ├── sample-2.out
│ ├── sample-3.in
│ ├── sample-3.out
│ ├── sample-4.in
│ └── sample-4.out
└── f
├── main.py
└── tests
├── sample-1.in
├── sample-1.out
├── sample-2.in
└── sample-2.out
12 directories, 41 files
テスト
プログラムが完成したら online-judge-tools にてテストを行う (atcoder-cli にはテストのコマンドは無い)
$ oj t -c "python3 main.py" -d ./tests/
提出
問題のディレクトリにて下記コマンドを行うことで自動で AtCoder のページに飛んで提出する。
$ acc s
参考
マンガで分かる統計学入門 で出てきた統計用語まとめ
はじめに
統計検定2級の勉強に マンガで分かる統計学入門 を読んだので、そこで出てきた統計用語についてまとめました。非常にわかりやすく統計学の導入におすすめです。
統計用語まとめ
- 度数分布表
- データをいくつかの階級に分けてその階級ごとの個数(これを度数または頻度という)を表にしたもの
- 度数
- 各階級に分類されたデータの個数のこと
- 分布しているとは、数値がばらけている様子のこと
- データの範囲とは、最大値と最小値との差
- 階級(クラス)、カテゴリとはデータの範囲をいくつかに分割した区間のこと。
- 階級の幅は必ずしも等しくする必要はない
- 階級境界値とは階級の境界の値
- 階級値とは階級境界値の中央の値
- ヒストグラム
- 度数分布表をグラフ化したもの
- 縦軸が度数、横軸を階級
- 階級の個数と幅の決め方によって大きく変わるため、度数分布の傾向、データ全体の傾向を見るために使う
- 相対度数とは、各階級の度数が全体の度数の中でどの程度を占めているかの指標
- 累積度数とは累積した度数の合計
- 累積相対度数とは、ある階級までに累積度数がすべての度数の中でどの程度を占めているかのしひ
統計指標
- 算術平均
- すべてのデータを合計して、総数で割った値
- 加重平均
- 各データごとの重要度を考慮した平均のこと
- メディアンは中央値
- モードは最頻値
- 分散とは、偏差を二乗した値を足してデータの総数ー1で割った値
- 分布の散らばり具合を知るための指標
- 二乗することでプラスとマイナスの値を同じに扱えるようにする
- 偏差
- 個々のデータから平均値を引いた値
- 標準偏差は分散の正の平方根
- 分散で二乗されたままだと、元のデータと単位が合わないので、平方根を取っている
- 標準化変量
- 標準化
- 偏差値
- 平均値50、標準偏差10の分布に従うように変換したもの
- 標準化変量 * 10 + 50
- 変動係数
- 数学の満点が100, 英語の満点が1000点で単位が異なるとき、分散を比較することはできない
- そこで変動係数 = 標準偏差 / 平均値 を用いると比較できるようになる
- 単位の問題を調整した分布のばらつきを示す統計指標
- 共分散
- 二つの異なる事象の相関関係を示す指標
- 相関関係はお互いの事象に関連があるという関係、因果関係は原因が結果を招くことはあっても、結果が原因を招くことはない関係
- https://mainichi.jp/articles/20170119/mul/00m/040/00600sc
- 相関関係
- イケメン度とチョコレートの数は相関がある
- 足の大きさとチョコレートの数は相関がない
- 因果関係
- イケメンだとチョコレートがたくさんもらえる
- チョコレートがたくさんもらえるからといってイケメンとは限らない
- 相関係数
- 算術平均
-
- 記述統計学
- 推測統計学
- 標本を分析して、母集団の特徴を推定、仮説検定する統計学のこと
- 母集団全体が大きすぎて全体を把握できないとか、今あるデータから未来に起こることを予測したい時に使う
- 株式市場のように何が起こるかわからない状況を取り扱うのは不確実性の世界という
- 一方、サイコロの目のようにどんな目が出るかわかっている状況をリスクの世界という
- 統計データを撮るときの調査対象の全体を母集団という
- クラスのテストだったら全員の点数を調べることはできるが、例えば政策を支持する党などを調査する時に全員に聞くことはできない
- こんな時に母集団から一部を取り出して、そこから推測する
- 標本
- 母集団から取り出した一部
- 無作為に抽出しないと結果が偏ってしまう
- 標本抽出
- 母集団から一部を取り出すこと
- 推定
- 母集団から取り出した標本から母集団の特性を推定すること
- 仮説検定
- 母集団の特性についての先験的仮説が経験的に観察されるデータと矛盾しないかどうかを確かめること
- 確率変数
- 推測統計学では階級値、相対度数、度数分布表を確率で記述する
- 実現値
- ある地点を過ぎて定まる値のこと
- 小文字で表す
- 確率変数
- 一つの無作為標本がどのような数値を取るのか不確実な場合、その標本は確率変数だといえる
- サイコロの目は1/6で出るので、1から6のように確率をともなう不確実な値のことを確率変数という
- 1から6は確率変数
- 大文字で表す
- 確率分布
- ある現象がいろいろな値を取り得るとき、取り得る値全体を確率変数として表す。どのような値をとるかは決まっていないが、取りうる値、もしくは取りうる値の範囲とその値をとる確率または確率密度が決まっている数のこと。一般に離散型と連続型の二つが用いられる。
- 離散型確率変数
- 株価の予想収益率のように -10, 5, 25といった不連続な値の時
- 分布関数
正規分布で将来を予測する
標本から母集団を推定
- 全数調査
- 母集団の要素が全てわかっているパターン
- 標本調査
- 無作為標本を調べる
- 母数
- 母集団の分布の特徴を示す数値
- 標本統計量
- 無作為標本の分布の特徴を示す数値
- 推定
- 全体を把握できない母集団があるとき、未知の母数を標本統計量によって推測する作業
- その推定した母数のことを推定量という
- 推定量は確率変数
- 標本の抽出のたびに推定量は変わるため
- 未知の母数の推定には二つの方法がある
- 統計的推定とは、正規分布にしたがう母集団から複数回の無作為抽出をしたときの一つの標本について考えること
- 標本平均を考えるときは場合分けが必要
- 有限母集団
- データ数が有限の場合
- 無限母集団
- データ数が無限の場合
- 有限母集団
- 中心極限定理
- 推定量の不遍性
- 母集団から無作為抽出された標本から標本平均を計算し、それを複数回行う。得られた複数の標本平均の期待値を求めたとき、母平均に等しくなること
- 推定量の一致性
- 標本に含まれるデータの数が増えていくと、標本平均が母平均とほぼ一致する
- 推定量の有効性
- 全数調査
母集団の推定方法 点推定と区間推定
- 仮説検定
- 仮説検定の方法 片側検定と両側検定
- 不偏推定量
- 平均的には真の値を正しく予測できるような推測量
- 標本分散はサンプルサイズが小さいと母分散よりも小さくなる
- 母平均に近づくようにサンプルを選ぶとすると、
- 二つの異なる母集団の平均の差の信頼区間
- 二つのデータが対応のだるデータか対応のないデータかによって算出方法が異なる
- 対応があるデータ
- 同じ対象に対する二つのデータのこと
- 二つのデータのサンプルサイズは必ず等しくなる
- 5人の1学期のテストと二学期のテストの点数の比較とか
- 標準誤差
- 母平均の信頼区間の求め方
- 母比率
- 母集団においてある事象が起こる確率
- 二項分布
- ベルヌーイ試行
- コインを投げたときに裏か表かのように、何かを行ったときに起こる事象が二つしかない試行のこと
- 二項分布とは、ベルヌーイ試行をn回行って、成功する回数が従う確率分布のこと
- 成功確率がpである試行をn回行うときに成功する回数をXとすると、Xは二項分布B(n, p)に従うが、このpが母比率
- ベルヌーイ試行
- 母比率
iOSアプリ WeekCal で AtCoder コンテストの日程を把握
手順は下記
- https://atcoder.jp/calendar から AtCoder コンテスト カレンダー公式があるが、ちゃんと更新されてないので下記を利用
- https://calendar.google.com/calendar/iphoneselect から表示したいカレンダーを追加。
- WeekCalアプリから対象のカレンダーを追加。

Python で AtCoder に参加するための環境準備1
記事の内容
AtCoder Begginner Contest に参加するときは、いつも AtCoder の環境(コードテスト)を利用していますが、少しでも提出までの時間を削減したいため、ローカルでテストができるように整備しています。まずは問題数分のファイルを生成するコードを作成しました。よく使う入出力コードをデフォルトで記載した .py ファイルが AからE問題分生成されます。
参考:http://www.kekeho.com/2019/03/atcoder-abc-script-for-vscode-python.html
コード
generate.py
import sys import os try: contest_num = sys.argv[1] except IndexError: print('Error: コンテストの番号を入力してください') exit() folder = f'abc_{contest_num}' files = [f'abc_{contest_num}_{problem}.py' for problem in ['a', 'b', 'c', 'd', 'e']] template = """S = input() S = input().split() N = int(input()) L = list(map(int, input().split())) a, b = map(int, input().split()) """ if not os.path.exists(folder): os.mkdir(folder) for file in files: with open('{}/{}'.format(folder, file), 'w') as f: f.write(template)
使い方
$ ls generate.py $ python generate.py 144 # 問題番号 $ ls abc_144 generate.py $ ls abc_144/ abc_144_a.py abc_144_b.py abc_144_c.py abc_144_d.py abc_144_e.py $ cat abc_144/abc_144_a.py S = input() S = input().split() N = int(input()) L = list(map(int, input().split())) a, b = map(int, input().split())
Kaggle IEEE 上位解法の理解と自身の反省、次のアクションについて
Kaggle IEEE にソロ参加しました。結果は・・・でしたが、学びが多かったので次回のコンペで活かせるように上位解法の理解と自身の反省、今後のアクションについてまとめました。
Very short summary - 1st place
- Main magic
- card, D, C, V カラムを使って、ユーザを特定しだいたい 600,000 くらいのカードとユーザを見つけた
- cardX, addrX, X_emaildomain の特徴量を使って uid を作っていた notebook はあった(下記コード参照)が、これだけでは特定
- 上記の uid を
pandas.DataFrame.aggを使って generalization し、学習データへの過学習を避ける - categorical features / supportive features for models
- card, D, C, V カラムを使って、ユーザを特定しだいたい 600,000 くらいのカードとユーザを見つけた
for df in [train, test]: df['uid1'] = df['card1'].astype(str) + '_' + df['card2'].astype(str) df['uid2'] = df['uid1'].astype(str) + '_' + df['card3'].astype(str) + '_' + df['card5'].astype(str) df['uid3'] = df['uid2'].astype(str) + '_' + df['addr1'].astype(str) + '_' + df['addr2'].astype(str) df['uid4'] = df['uid3'].astype(str) + '_' + df['P_emaildomain'].astype(str) df['uid5'] = df['uid3'].astype(str) + '_' + df['R_emaildomain'].astype(str)
Features validation
- Train 2 month / skip 2 / predict 2
- Train 4 / skip 1 / predict 1
- スキップをはさんでいるのは、TrainとTestデータの間に間隔があるからだと思われる。Validationの分割は、TrainとTestの分割と同じ方法で行うのが定石( How to Win a Data Science Competition からの学び)
Models
- Catboost (0.963915 public / 0.940826 private)
- LGBM (0.961748 / 0.938359)
- XGB (0.960205 / 0.932369)
- Predictions
- 6 folds / GroupKfold by month
1st Place Solution - Part 1
Time は重要ではなかった
- Adversarial Validation で AUC ≒ 1 だったのは、fraud の性質が変化したからではなく、データセット内のユーザが変化したから
- Adversarial Validation の Notebook は こちら
- Adversarial Validation の日本語解説は Python: Adversarial Validation について
- private dataset のデータセットをプロットすると、68.2% が train に存在しないユーザで、16.4% が 両者に存在するユーザ
- Adversarial Validation で AUC ≒ 1 だったのは、fraud の性質が変化したからではなく、データセット内のユーザが変化したから
Magic Feature
- コンペのホストが ここ で発言しているように、一度ユーザ(クレジットカードが)が fraud とされるとそのアカウントの fraud が 1 になる。つまり、今回のコンペは fraudulent transactions ではなく fraudulent clients (credit card) を予測するタスクだったと言える
Fraudulent Clients
for df in [train, test]: df['day'] = df['TransactionDT'] / (24*60*60) df['card1_addr1'] = df['card1'] + '_' + df['addr1'] df['uid'] = df[card1_addr1.astype(str) + '_' + np.floor(df['day'] - df['D1']).astype(str)
- Preventing Overfitting
- uid をそのまま使うともちろん過学習してしまうため、aggregated feature を作成
- 例えば、Cx, Mx カラムを使って
new_features = df.groupby('uid')[CM_columns].agg(['mean'])- なぜ aggregated feature を作ると判別できるようになるのかについては、How the Magic Works の説明がわかりやすい
- 最後に過学習を避けるため uid を削除
- これでモデルは未知のユーザかどうかを分類できるようになる
- aggregated feature はこんなイメージ
- 例えば、Cx, Mx カラムを使って
- uid をそのまま使うともちろん過学習してしまうため、aggregated feature を作成
agg_types = ['max', 'min', 'sum', 'mean', 'std', 'count'] for agg_type in agg_types: new_col_name = cat_col + '_' + agg_col + '_' + agg_type temp = pd.concat([train[[cat_col, agg_col]], test[[cat_col, agg_col]]]) temp = temp.groupby([cat_col])[agg_col].agg([agg_type]).reset_index().rename(columns={agg_type: new_col_name}) temp.index = list(temp[cat_col]) temp = temp[new_col_name].to_dict() train[new_col_name] = train[cat_col].map(temp) test[new_col_name] = test[cat_col].map(temp)
1st Place Solution - Part 2
- Final Model
- CatBoost (Public/Private LB of 0.9639/0.9408), LGBM (0.9617/0.9384), and XGB (0.9602/0.9324)
- それぞれ別々の特徴量エンジニアリングをしていたので、多様性があった
- final submission は Catboost の予測結果を利用した LightGBMのスタッキングと他のモデルの アンサンブル (equal weight)
- それらの結果は、post process として同じ client は Client ごとのスコアの平均に書き換えることでスコアを伸ばせた
- CatBoost (Public/Private LB of 0.9639/0.9408), LGBM (0.9617/0.9384), and XGB (0.9602/0.9324)
How to FInd UIDs
- 具体的な方法については ここ
- 430 columns の中から顧客を特定するための特徴量はどれか
- trainとtestデータに含まれる顧客の多くは異なっている
Transaction_day - D系カラムをしてから、最初の53の特徴量を利用して Adversarial Validation をすると 0.999 になった。つまりこれらの特徴量は顧客を識別するのに重要だとわかる- D10n, D1n, D15n, C13, D4n, card1, D2n, card2, addr1, TransactionAmt, dist1 が最も重要だと判断した
- Adversarial Validation で feature importance を上から見ていけばこれらが出てくるはず
- V系のカラムについて
- これも同じくV系特徴量だけで Adversarial Validation を行ったところ、AUC = 0.999 となった
- 最終的に encode_AG(['V127','V136','V307','V309','V314,'V320`] ,['uid'], ['nunique']) で特徴量を作成
-
- IEEE Transaction columns Reference を参考に
- V系カラムの次元削減を行った
- NANの傾向からグループを作成
- グループごとに PCA を行った
- グループから 最も相関が少ない特徴を選択
- それぞれのグループを全カラムの平均で置き換える
- 特徴選択
- 今回はたくさんカラムがあるので特徴選択はとても重要
- XGBのモデルは 250 カラム
- 使ったトリックは下記
- forward feature selection (using single or groups of features)
- recursive feature elimination (using single or groups of features)
- permutation importance
- adversarial validation
- correlation analysis
- time consistency
- 1つまたはグループの特徴量を使って、学習データの初めの月だけを利用してシングルモデルを学習させ、学習データの最後の月を使って予測をする。これである特徴量が時間を超えて一貫性があるかを判断することができる。
- 5%の特徴量がモデルの精度を下げた。これはつまりモデルはあるパターンを見つけたが、未来にはそれは存在していなかったといえる。
- 精度を下げた特徴量については取り除いたという理解
- client consistency
- train/test distribution analysis
- バリデーションの戦略
- 特定のバリデーションを信頼してなかったので、たくさんの方法を試した
- Trainの最初の2ヶ月分を学習、1ヶ月をスキップ、最後の1ヶ月を予測
- Trainの最初の2ヶ月分を学習、2ヶ月をスキップ、最後の2ヶ月を予測
- Trainの最初の1ヶ月分を学習、4ヶ月をスキップ、最後の1ヶ月を予測
- 特定のバリデーションを信頼してなかったので、たくさんの方法を試した
2nd Solution, CPMP View
Data Cleaning
- 各特徴量ごとに train と test の distribution をチェック
- raw feature と frequency encoding feature をプロット
- raw feature の場合、train と test の分布に差があるが、frequency encoding feature の分布には差がないので raw feature は削除して、frequency encoding feature を利用した
Cross Validation
- train と test の間には時間的ギャップが存在すること、test が train から数ヶ月離れていることをCVで再現しようとした
- 結果的に下記の folds にした
- 0 | 2 3 4 5 6
- 0 1 | 3 4 5 6
- 0 1 2 | 4 5 6
- 0 1 2 3 | 5 6
- 上記の CV で AUC の平均をとった
- この CV で特徴量の評価、特徴選択とハイパーパラメータの最適化を行った
Feature Engineering
- まずは全特徴量の frequency encodin を行って LightGBM で上記の CV を行い、permutation importance から特徴量選択を行った
- permutation importance の概要については Permutation Importanceを使ってモデルがどの特徴量から学習したかを定量化する がわかりやすい
- permutation 後にモデルが改善しなければその特徴量を保持した
- これによっていくつかの特徴量を削除した
- いくつかの uid 候補があったが最終的に下記を使った
data['uid1'] = (data.day - data.D1).astype(str) +'_' + data.P_emaildomain.astype(str) data['uid2'] = (data.card1.astype(str) +'_' + data.addr1.astype(str) +'_' + (data.day - data.D1).astype(str) +'_' + data.P_emaildomain.astype(str))
def add_gr(data, col): cols = data.columns gr = data.groupby(col) data[col+'_count'] = gr.TransactionID.transform('count').astype('int32') data[col+'_next_dt'] = gr.TransactionDT.shift(-1) data[col+'_next_dt'] -= data.TransactionDT data[col+'_mean_dt'] = gr[col+'_next_dt'].transform('mean').astype('float32') data[col+'_std_dt'] = gr[col+'_next_dt'].transform('std').astype('float32') data[col+'_median_dt'] = gr[col+'_next_dt'].transform('median').astype('float32') data[col+'_next_amt'] = gr.TransactionAmt.shift(-1) data[col+'_mean_amt'] = gr.TransactionAmt.transform('mean').astype('float32') data[col+'_std_amt'] = gr.TransactionAmt.transform('std').astype('float32') data[col+'_median_amt'] = gr.TransactionAmt.transform('median').astype('float32') new_cols = list(set(data.columns) - set(cols) -set([col+'_next_dt'])) return new_cols
- Final Blend
9th place solution notes
だいたい1位のソリューションと同じ。
- 同じユーザに属するトランザクションを特定することに重きを置いていた(他のトップチームも同じはず)
- ユーザを特定するのには、
"2017-11-30" + TransactionDT - D1が効いた- 同様に別のD系カラムにも適用した
- またユーザの特定には V95, V97, V96, V126, V128, V127 を利用した
- これらをどう特定したのかは書かれてはいない
- ユーザ特定をした結果を特徴量ではなく、post processing、pseudo labeling に利用した
- 最初の3ヵ月分を学習、1ヵ月分をスキップ、2ヵ月をバリデーションに使った。
- これらは public LB には相関していたが、private LB ではうまくいかなかった
- モデルは LightGBM, Catboost and XGBoost を利用
学び・反省
- ホストの発言やD1カラムについては Discussion で公開されていて、uid系特徴量を作成している notebook もあったので、Discussion をちゃんと読んでいれば顧客 (クレジットカード)を特定するタスクととらえることは難しくなかったかもしれない
- 大きなヒントが隠れているので当たり前だが Discussion をちゃんと読むことは大事
- 特に今回については、Data Description (Details and Discussion) をきちんと読み込むことが重要だった
- コンペのホストの発言 には upvote がたくさんついていたので気づくことは難しくなかった
- EDAから仮説を立てて特徴量を作ることがあまり得意ではないことを理解した
- 今回のコンペで EDA や 特徴量エンジニアリングにおけるスニペットを作成できたので、次回から使いまわせるはず
- Discussion での英語は全く抵抗がなくなって、以前よりも辞書で意味を調べることも少なくなったので余計な時間が取られなくなった
- 分からない単語は Quizlet という単語帳サービスを使ってまとめて、暇なときに見返すようにしていたのでそれがうまくいっているのかも
- スプレッドシートで追加した特徴量と Local CV、LBスコア、カーネルのURL などをまとめるようにしてみた
- 特徴量エンジニアリングの試行錯誤で同じことをすることが避けられた
- もっとスマートな管理ができたら良い

- Feature Engineering Techniques は他のコンペでも使える知識
- テーブルデータコンペでもNNを使えるようになりたい
- アンサンブルに効いてくるし、得意な人もあまりいないと思うのでできるようになれば、チームマージ力が上がる(笑)
- LB9564 NN solution overview は参考になる
次のアクション
- 引き続き本コンペの上位解法を読む
- discussion を読むだけで終わらず、実際に自分で実装してスコアが上がるところまでやりきる
- EDAから仮説構築 -> 特徴量エンジニアリング ができるように、終わったコンペでもいいので取り組んでみる
- Kaggleで勝つデータ分析の技術 を買ったので全部読み切る
- NFL Big Data Bowl に参加してソロでメダルを取る!
Kaggle テーブルデータコンペで使う EDA・特徴量エンジニアリングのスニペット集
随時追加していきます。間違いやもっとこうした方がいいなどあればコメントください。
前提
import pandas as pd import multiprocessing import numpy as np import seaborn as sns import sys from itertools import chain from collections import deque import matplotlib.pyplot as plt from pandas.io.json import json_normalize import json import warnings train = pd.read_csv("../input/train.csv") test = pd.read_csv("../input/test.csv")
EDA
データの確認
Notebook でデータを見る前に、コンペの Data > Data Description から、各データ・カラムの概要を理解する。場合によっては、csv でダウンロードして、スプレッドシートとして眺めてみる。
コンペデータのファイルを確認
!ls -GFlash /kaggle/input/<コンペ名称>/
例えば、2019 Data Science Bowl では、下記のように表示される。データの種類や、サイズなどを確認できる。
!ls -GFlash /kaggle/input/data-science-bowl-2019/ total 4.0G 4.0K drwxr-xr-x 2 root 4.0K Oct 23 16:22 ./ 4.0K drwxr-xr-x 3 root 4.0K Oct 26 04:05 ../ 12K -rw-r--r-- 1 root 11K Oct 23 16:21 sample_submission.csv 400K -rw-r--r-- 1 root 400K Oct 23 16:21 specs.csv 380M -rw-r--r-- 1 root 380M Oct 23 16:22 test.csv 3.7G -rw-r--r-- 1 root 3.7G Oct 23 16:22 train.csv 1.1M -rw-r--r-- 1 root 1.1M Oct 23 16:21 train_labels.csv
データをランダムサンプリングする
1000000 レコードでランダムサンプリングする場合。データが大きすぎて、EDAでデータをプロットするのに時間がかかってしまう時などに利用する。
train_sampled = train.sample(1000000)
print(train.shape) train_sampled = train.sample(1000000) print(train_sampled.shape) -------------- (11341042, 11) (1000000, 11)
warningを表示しないようにする
warnings.filterwarnings('ignore')
データフレームの表示数を増やす
head 等で表示した際に省略されないようにする
pd.set_option('display.max_rows', None) pd.set_option('display.max_columns', None) pd.set_option("display.max_colwidth", 10000)
行数と列数を表示する
print("{} rows and {} features in train set".format(train.shape[0], train.shape[1])) print("{} rows and {} features in test set".format(test.shape[0], test.shape[1]))
メモリ使用量を減らす
def reduce_mem_usage(df): start_mem = df.memory_usage().sum() / 1024**2 print('Memory usage of dataframe is {:.2f} MB'.format(start_mem)) for col in df.columns: col_type = df[col].dtype if col_type != object: c_min = df[col].min() c_max = df[col].max() if str(col_type)[:3] == 'int': if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max: df[col] = df[col].astype(np.int8) elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max: df[col] = df[col].astype(np.int16) elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max: df[col] = df[col].astype(np.int32) elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max: df[col] = df[col].astype(np.int64) else: if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max: df[col] = df[col].astype(np.float16) elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max: df[col] = df[col].astype(np.float32) else: df[col] = df[col].astype(np.float64) else: df[col] = df[col].astype('category') end_mem = df.memory_usage().sum() / 1024**2 print('Memory usage after optimization is: {:.2f} MB'.format(end_mem)) print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem)) return df
train = reduce_mem_usage(train) test = reduce_mem_usage(test)
下記のように メモリ使用量 を最適化してくれる
Memory usage of dataframe is 1959.88 MB Memory usage after optimization is: 530.08 MB Decreased by 73.0% Memory usage of dataframe is 1677.73 MB Memory usage after optimization is: 462.08 MB Decreased by 72.5%
並列処理でデータを read する
data ディレクトリにあるファイルをメモリ使用量を減らしつつ、並列処理でデータフレームとして読み込む。
path = "/kaggle/input/<コンペ名称>/" data_list = glob(path + '*.csv') def load_data(data): return reduce_mem_usage(pd.read_csv(data)) with multiprocessing.Pool() as pool: sample, test, train = pool.map(load_data, data_list)
pandas 基本
train.dtypes train.info() train['col_name'].value_counts() train.shape train.columns train.query('col_name < 0') train['col_name'].unique() train.drop_duplicates() train.isna()
カラムごとのユニーク数とユニーク値の表示
for col, values in train.iteritems(): num_uniques = values.nunique() print ('{name}: {num_unique}'.format(name=col, num_unique=num_uniques)) print (values.unique()) print ('\n')
統計量の表示
カラム名 / カラムごとのユニーク値数 / 最も出現頻度の高い値 / 最も出現頻度の高い値の出現回数 / 欠損損値の割合 / 最も多いカテゴリの割合 / dtypes を表示する。
%%time stats = [] for col in train.columns: stats.append((col, train[col].nunique(), train[col].value_counts().index[0], train[col].value_counts().values[0], train[col].isnull().sum() * 100 / train.shape[0], train[col].value_counts(normalize=True, dropna=False).values[0] * 100, train[col].dtype)) stats_df = pd.DataFrame(stats, columns=['Feature', 'Unique values', 'Most frequent item', 'Freuquence of most frequent item', 'Percentage of missing values', 'Percentage of values in the biggest category', 'Type']) stats_df.sort_values('Percentage of missing values', ascending=False)
例えば、2019 Data Science Bowl では、下記のように表示される。
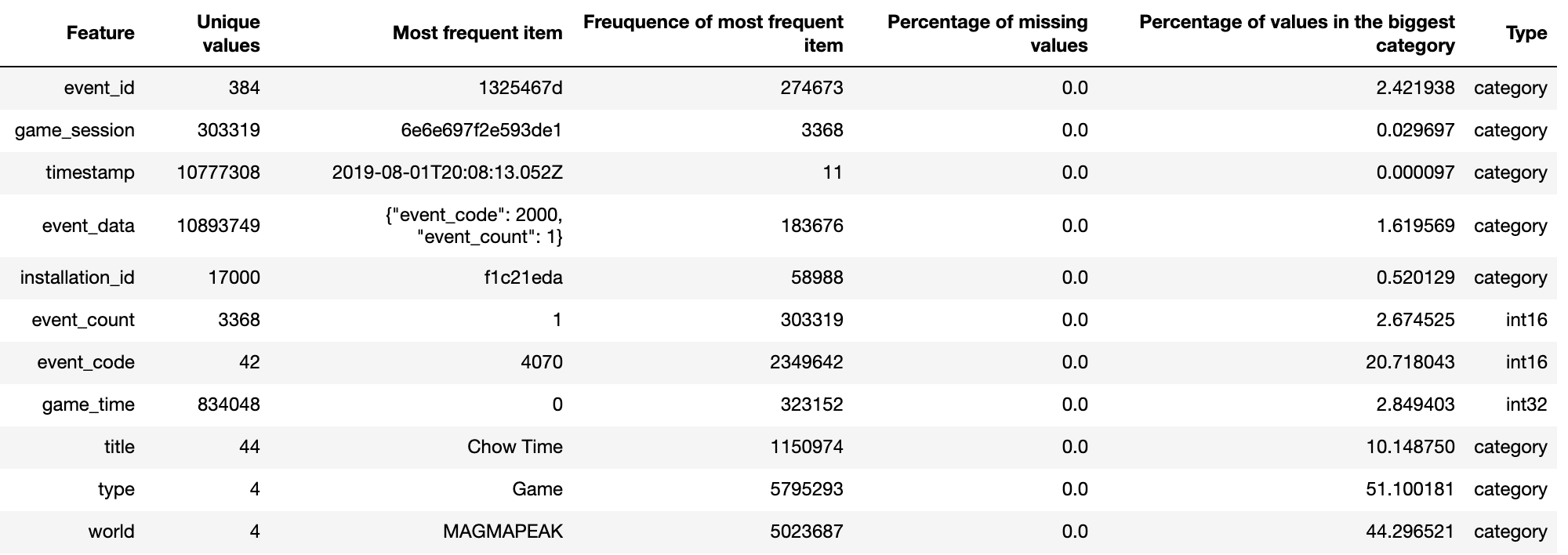
参考:https://www.kaggle.com/artgor/is-this-malware-eda-fe-and-lgb-updated
全カラムのヒストグラム表示
train.hist(bins=50, figsize=(80,60)) plt.show()
特定のカラムのヒストグラム表示
train['col_name'].plot(kind='hist', bins=200, figsize=(15, 5), title='Distribution of col_name') # log scaleの場合 train['col_name'].apply(np.log).plot(kind='hist', bins=200, figsize=(15, 5), title='Distribution of col_name') plt.show()
2値分類タスクで target のカテゴリごとに特定のカラムのヒストグラムを表示
log scale した場合
fig, (ax1, ax2) = plt.subplots(2, figsize=(15, 6)) train[train['target'] == 1]['col_name'].apply(np.log).plot(kind='hist', bins=100, title='Log col name - 1', color='#348ABD', xlim=(-3, 10), ax=ax1) train[train['targe'] == 0]['col_name'].apply(np.log).plot(kind='hist', bins=100, title='Log col name - 0', color='#348ABD', xlim=(-3, 10), ax=ax2) plt.show()
散布図
plt.figure(figsize=(15, 5)) plt.scatter(train['x_cols'], train['y_cols']) plt.title('title') plt.xlabel('x_col_name') plt.ylabel('y_col_name') plt.show()
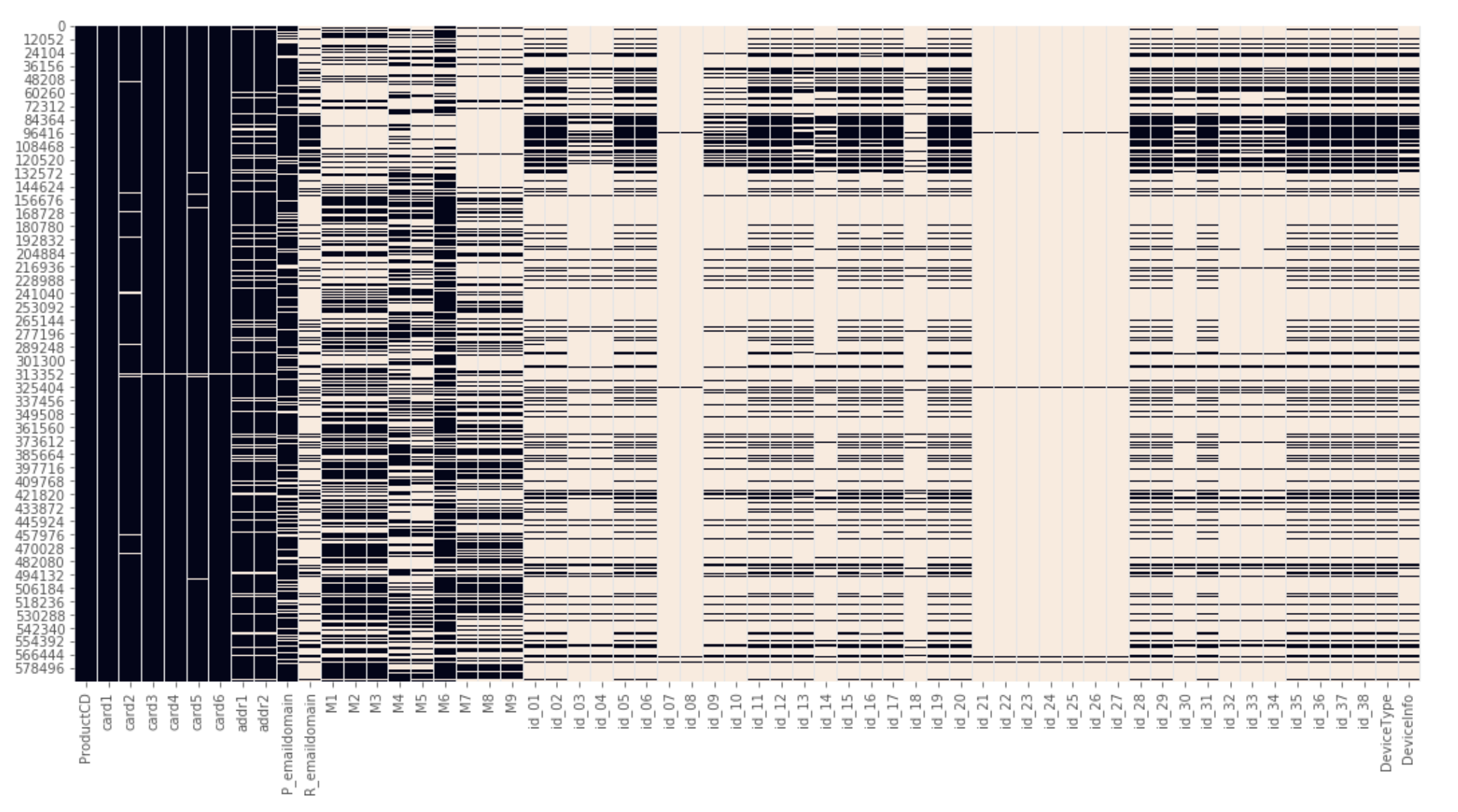
欠損値をヒートマップで視覚化
データ全体における欠損値を概要を理解する
plt.figure(figsize=(18,9)) sns.heatmap(train.isnull(), cbar=False)
欠損している箇所が白く表示されるため、全体としてどのようにデータが欠損しているか理解できる。 参考:https://www.kaggle.com/suoires1/fraud-detection-eda-and-modeling より
特徴量同士の相関をヒートマップで表示
fig, ax = plt.subplots(figsize=(12, 9)) sns.heatmap(train.corr(), square=True, vmax=1, vmin=-1, center=0)
ターゲットとその他の特徴量との相関
train.corr()['target'].sort_values()
分類タスクにおけるターゲット変数の割合
train['target'].value_counts()
変数のメモリ使用量を表示する
def compute_object_size(o, handlers={}): dict_handler = lambda d: chain.from_iterable(d.items()) all_handlers = {tuple: iter, list: iter, deque: iter, dict: dict_handler, set: iter, frozenset: iter, } all_handlers.update(handlers) # user handlers take precedence seen = set() # track which object id's have already been seen default_size = sys.getsizeof(0) # estimate sizeof object without __sizeof__ def sizeof(o): if id(o) in seen: # do not double count the same object return 0 seen.add(id(o)) s = sys.getsizeof(o, default_size) for typ, handler in all_handlers.items(): if isinstance(o, typ): s += sum(map(sizeof, handler(o))) break return s return sizeof(o) def show_objects_size(threshold, unit=2): disp_unit = {0: 'bites', 1: 'KB', 2: 'MB', 3: 'GB'} globals_copy = globals().copy() for object_name in globals_copy.keys(): size = compute_object_size(eval(object_name)) if size > threshold: print('{:<15}{:.3f} {}'.format(object_name, size, disp_unit[unit])) # 100MB超のオブジェクト一覧を表示する show_objects_size(100)
参考:https://qiita.com/nannoki/items/1466779987b68c4f4bf9
データのカラムリストから 特定のカラムを取り除いたリストを取得する
drop_cols = ['a', 'b', 'c', 'd', 'e'] # 取り除きたいカラムのリスト cols = [c for c in train.columns if c not in drop_cols]
データフレームへの処理の並列化
def df_parallelize_run(df, func): num_partitions, num_cores = psutil.cpu_count(), psutil.cpu_count() df_split = np.array_split(df, num_partitions) pool = multiprocessing.Pool(num_cores) df = pd.concat(pool.map(func, df_split)) pool.close() pool.join() return df
特徴量エンジニアリング
特定の文字を含んだカラム名のリストを得る
# 'target' という文字を含んだカラムを取得 cols = [c for c in train.columns if 'target' in str(c)]
json 形式のカラムを複数のカラムに展開する
df_json = json_normalize(train['json_col'].apply(lambda x: json.loads(x)))
複数の情報を含んだカラムを分割する
Android 6.0.1、iOS 11.4.0 といった OSとバージョン情報を複数含んだカラムを分割する。
# アンダーバーで分割 train['OS'] = train['OS_VERSION'].str.split('_', expand=True)[0] train['VERSION'] = train['OS_VERSION'].str.split('_', expand=True)[1]
Count Encoding
カテゴリ変数の列で各カテゴリの出現回数をカウント。ここでは、train と test における出現回数を合計した特徴量を生成。カテゴリ値の人気度を測定しているようなものと解釈する。 参考:https://blog.datarobot.com/jp/automatedfeatureengineering
train['col_name_count'] = train['col_name'].map(pd.concat([train['col_name'], test['col_name']], ignore_index=True).value_counts(dropna=False)) test['col_name_count'] = test['col_name'].map(pd.concat([train['col_name'], test['col_name']], ignore_index=True).value_counts(dropna=False))
clipping
# 99% upperbound, lowerbound = np.percentile(train['col_name'], [1, 99]) train['col_name_clipped'] = np.clip(train['col_name'], upperbound, lowerbound)
normalize
train['col_name_nomalize'] = (train['col_name'] - train['col_name'].mean() ) / train['col_name'].std()
カテゴリ変数のみ Label Eoncoding する
from sklearn.preprocessing import LabelEncoder for col in train.columns: if train[col].dtype == 'object': le = LabelEncoder() le.fit(list(train[col].astype(str).values) + list(test[col].astype(str).values)) train[col] = le.transform(list(train[col].astype(str).values)) test[col] = le.transform(list(test[col].astype(str).values))
行のNAN数を新しい特徴量に
train['number_of_NAN'] = train.isna().sum(axis=1).astype(np.int8)
ビニング処理
ビンに含まれる個数を指定
df['col_name_qcut_10'] = pd.qcut(df['col_name'], 10)
test データに無い場合1、ある場合は0にする特徴量
train['col_name_check'] = np.where(train['col_name'].isin(test['col_name']), 1, 0) # test の場合は逆 test['col_name_check'] = np.where(test['col_name'].isin(train['col_name']), 1, 0)
全て0のカラムを作成する
train["col_name_zero"] = np.zeros(train.shape[0])
NaN とそれ以外の値の特徴量を作成する
train['col_name_nan'] = np.where(train['col_name'].isna(), 1, 0)
nan 数の同じカラムごとにグループ化
nans_groups = {}
nans = pd.concat([train, test]).isna()
for col in train.columns:
cur_group = nans[col].sum()
if cur_group > 0:
try:
nans_groups[cur_group].append(col)
except:
nans_groups[cur_group] = [col]
for n_group, n_members in nans_groups.items():
print(n_group, len(n_members), n_members)
Aggregated Features
カテゴリのグループごとに aggregation する。例えば、同じip, os, deviceの総クリック数を計算するなど。参考:Kaggle Masterに学ぶ実践的機械学習[Kaggle TalkingData Competition編]
agg_types = ['max', 'min', 'sum', 'mean', 'std', 'count'] for agg_type in agg_types: new_col_name = cat_col + '_' + agg_col + '_' + agg_type temp = pd.concat([train[[cat_col, agg_col]], test[[cat_col, agg_col]]]) temp = temp.groupby([cat_col])[agg_col].agg([agg_type]).reset_index().rename(columns={agg_type: new_col_name}) temp.index = list(temp[cat_col]) temp = temp[new_col_name].to_dict() train[new_col_name] = train[cat_col].map(temp) test[new_col_name] = test[cat_col].map(temp)
numeric feature を 0以上にシフトする
for col in train.columns: if not ((np.str(train[col].dtype)=='category')|(train[col].dtype=='object')): min = np.min((train[col].min(), test[col].min())) train[col] -= np.float32(min) test[col] -= np.float32(min)
numeric feature の 欠損値を -1 で埋める
for col in train.columns: if not ((np.str(train[col].dtype)=='category')|(train[col].dtype=='object')): train[col].fillna(-1, inplace=True) test[col].fillna(-1, inplace=True)
frequency encoding
カテゴリ変数の出現回数で変数を置き換える。
def freq_enc(train, test, cols): for col in cols: df = pd.concat([train[col], test[col]]) vc = df.value_counts(dropna=True, normalize=True).to_dict() vc[-1] = -1 # 欠損値を -1 で埋める場合 new_col = col + '_freq_enc' train[new_col] = train[col].map(vc) train[new_col] = train[new_col].astype('float32') test[new_col] = test[col].map(vc) test[new_col] = test[new_col].astype('float32') freq_enc(train, test, feature_list)
特徴量同士を結合した特徴量を作成し Label Encoding
def conb_enc(col1, col2, train, test): nm = col1 + '_' + col2 train[new_col] = train[col1].astype(str) + '_' + train[col2].astype(str) test[new_col] = test[col1].astype(str) + '_' + test[col2].astype(str) le = LabelEncoder() le.fit(list(train[new_col].astype(str).values) + list(test[new_col].astype(str).values)) train[new_col] = le.transform(list(train[new_col].astype(str).values)) test[new_col] = le.transform(list(test[new_col].astype(str).values))
あるカラム群の欠損の数の合計を特徴量にする
train['missing'] = train[col_list].isna().sum(axis=1).astype('int16') test['missing'] = test[col_list].isna().sum(axis=1).astype('int16')
特徴選択
constant なカラムを抜き出す
90%以上、同じ値のカラムを抜き出す
def get_constant_cols(df): constant_cols = [col for col in df.columns if df[col].value_counts(dropna=False, normalize=True).values[0] > 0.9] return constant_cols cols = get_constant_cols(train)
不要なカラムを落とす
- 値が一つしかないカラム
- null が多いカラム
- ほとんど同じ値のカラム
one_value_cols = [col for col in train.columns if train[col].nunique() <= 1] one_value_cols_test = [col for col in test.columns if test[col].nunique() <= 1] many_null_cols = [col for col in train.columns if train[col].isnull().sum() / train.shape[0] > 0.9] many_null_cols_test = [col for col in test.columns if test[col].isnull().sum() / test.shape[0] > 0.9] big_top_value_cols = [col for col in train.columns if train[col].value_counts(dropna=False, normalize=True).values[0] > 0.9] big_top_value_cols_test = [col for col in test.columns if test[col].value_counts(dropna=False, normalize=True).values[0] > 0.9] cols_to_drop = list(set(many_null_cols + many_null_cols_test + big_top_value_cols + big_top_value_cols_test + one_value_cols+ one_value_cols_test)) train.drop(cols_to_drop, axis=1, inplace=True) test.drop(cols_to_drop, axis=1, inplace=True)
再帰的特徴量選択
from sklearn.feature_selection import RFE from sklearn.ensemble import RandomForestClassifier X_train = train.drop('target', axis=1) y_train = train['target'] select = RFE(RandomForestClassifier(n_estimators=100, random_state=42), n_features_to_select=40) select.fit(X_train, y_train) X_train_rfe = select.transform(X_train) X_test_rfe = select.transform(test)
コルモゴロフ-スミルノフ検定を利用した特徴量選択
from scipy.stats import ks_2samp list_p_value =[] for i in tqdm(train.columns): list_p_value.append(ks_2samp(test[i], train[i])[1]) Se = pd.Series(list_p_value, index=train.columns).sort_values() list_discarded = list(Se[Se < .1].index)
参考:https://www.kaggle.com/c/elo-merchant-category-recommendation/discussion/77537
Null Importance による特徴量選択
LightGBM などの学習器における feature importance で、上位に来た特徴量の中にノイズになっているものが含まれていることがある。そこで正しい目的変数で学習した結果の feature importance と目的変数を shuffle したデータを用いて学習した結果の feature importance を比較することでノイズになっている特徴量を抽出する。
def get_feature_importances(X, shuffle, seed=None): cols_to_drop = ['col_to_drop_1','col_to_drop_2'] categoricals = ['cat_col'] y = X['target'] X = X.drop(cols_to_drop, axis=1) if shuffle: y = np.random.permutation(y) train = lgb.Dataset(X, y, free_raw_data=False, silent=True) lgb_params = { 'objective': 'binary', 'boosting_type': 'rf', 'subsample': 0.623, 'colsample_bytree': 0.7, 'num_leaves': 127, 'max_depth': 8, 'seed': 42, 'bagging_freq': 1, 'n_jobs': 4 } clf = lgb.train(params=lgb_params, train_set=train, num_boost_round=200, categorical_feature=categoricals) df_importance = pd.DataFrame() df_importance["feature"] = list(X.columns) df_importance["importance"] = clf.feature_importance() df_importance['train_score'] = roc_auc_score(y, clf.predict(X)) # 二値分類の場合 return df_importance def display_distributions(df_actual_importance, df_null_importance, feature): actual_imp = df_actual_importance.query(f"feature == '{feature}'")["importance"].mean() null_imp = df_null_importance.query(f"feature == '{feature}'")["importance"] fig, ax = plt.subplots(1, 1, figsize=(6, 4)) a = ax.hist(null_imp, label="Null importances") ax.vlines(x=actual_imp, ymin=0, ymax=np.max(a[0]), color='r', linewidth=10, label='Real Target') ax.legend(loc="upper right") ax.set_title(f"Importance of {feature.upper()}", fontweight='bold') plt.xlabel(f"Null Importance Distribution for {feature.upper()}") plt.ylabel("Importance") plt.show() # 実際の目的変数で学習し、feature importance の DataFrame を作成 df_actual_importance = get_feature_importances(X=reduce_train, shuffle=False) # シャッフルした目的変数で学習し、feature importance の DataFrame を作成 nb_runs = 100 df_null_importance = pd.DataFrame() for i in range(nb_runs): df_importance = get_feature_importances(X=reduce_train, shuffle=True) df_importance["run"] = i + 1 df_null_importance = pd.concat([df_null_importance, df_importance]) # 実データにおいて特徴量の重要度が高かった上位5位を表示 for feature in actual_imp_df["feature"][:5]: display_distributions(df_actual_importance, df_null_importance, feature) # 閾値を設定 THRESHOLD = 80 # 閾値以下(ノイズ)の特徴量を取得 not_important_features = [] for feature in df_actual_importance["feature"]: actual_value = df_actual_importance.query(f"feature=='{feature}'")["importance_split"].values null_value = df_null_importance.query(f"feature=='{feature}'")["importance_split"].values percentage = (null_value < actual_value).sum() / null_value.size * 100 if percentage < THRESHOLD: not_important_features.append(feature)
参考
その他参考にする記事
AWS認定試験勉強の後半戦は Whizlabs で問題を解きまくるといい
はじめに

最近AWS認定ソリューリョンアーキテクトアソシエイト(SAA)の資格を取得しました。取得スコアは867、合格に必要なスコアは720だったので、悪くない点数が取れたかと思います。
勉強法については、Qiitaやブログなどを参考にしました。例えば AWS認定11冠制覇したのでオススメの勉強法などをまとめてみる など参考になる記事はたくさんあり、おすすめ通りの勉強を1ヶ月ほど行いました。ある程度知識がついたので模擬試験を受けましたが問題数は25問のみだったので、間違えた問題を復習しても本番には少し不安が残っていました。
そこで、ネット上でSAAの問題がたくさん解けるサービスがないかと探していたところ、Whizlabsという practice test のコースがたくさんある海外のサイトを見つけたので簡単に紹介します。
Whizlabs とは?
online certification training サービスで、様々な資格試験のためのトレーニングを受講することができます。AWS認定試験のコースについては、おそらく全ての種類の試験のトレーニングが存在するようです。GCP や Azure など、その他のクラウドの資格試験もあります。
SAAのサンプル問題を解いてみる
では、実際に SAA のサンプル問題を Whizlabs で解いてみましょう。 AWS Certified Solutions Architect Associate (SAA-C01) のページの Free Test を選択し会員登録します。(ここまで無料)
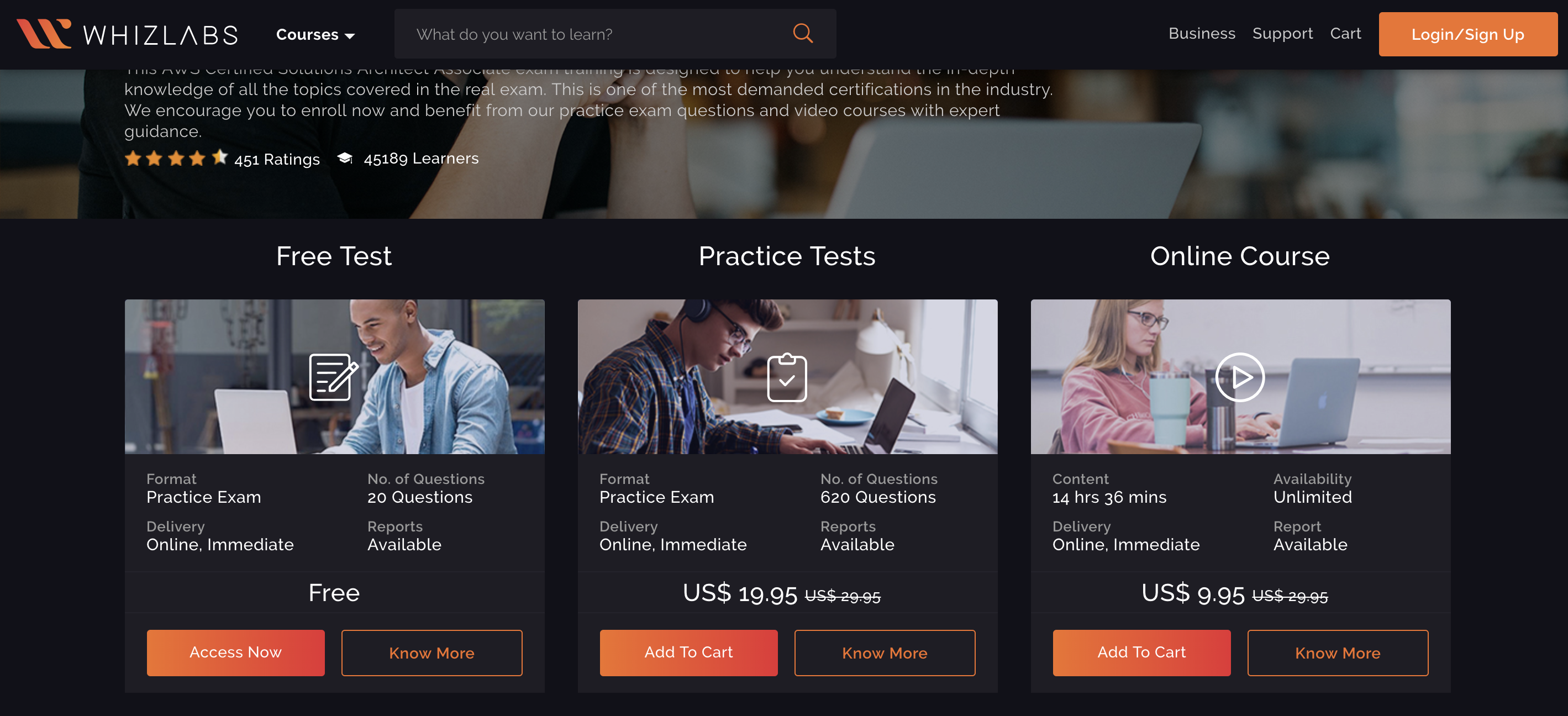
画面としてはこんな感じで、問題と右側には何問中何問まで解いたか、あとでレビューするためのチェックボックスなど、とても使いやすい設計となっています。

公式の模擬試験ではスコアはでましたが解答はないです。Whizlabs では、1問1問解答を確認できるため、すぐに復習をできる点がとても良いです。
問題を解きまくる
Free Test を解いて使えそうだなと思ったら $19.95(2000円弱)を支払って Practice Tests で問題を解きまくりましょう。トータルでは620問ほどあり、これを全て解いたら確実に合格に近くと思います。自分の場合は65問ほど解いて、不明点は BlackBelt を読んで納得するというのを行なって合格できました。資格のための勉強という側面だけでなく、業務でも普通に使える知識が幅広くついたので受験してよかったなと思っています。
まとめ
ある程度の知識がついたらあとは本番の試験を想定した問題をたくさん解くというのは資格試験においては定石であるため、それができる Whizlabs は合格に近くいいサービスだと思います。英語に抵抗がなく2000円程度で支払っても良いのであれば後半戦におけるおすすめの勉強法です。
AWS東京リージョンで発生したシステム障害についてのまとめ
AWS東京リージョンで発生したシステム障害について、普段AWSに触れることがない人でも理解できるようにまとめてみました。アップデートがあり次第更新予定です。
起こった事象
AWSの東京リージョンにおける単一アベイラビリティゾーン(AZ)に存在する一部のEC2、EBS、RDSにおいて接続できない問題が発生しました。また当該事象が起こったタイミングでAWSのマネジメントコンソール(管理操作画面)への接続もしづらい状況が続きました。
リージョン、アベイラビリティゾーンについて
AWSクラウドは現在22の地理的リージョンにある69のアベイラビリティゾーンで運用されています。例えば、米国東部(バージニア北部)リージョンやアジアパシフィック (シンガポール)などが存在します。そして各リージョンには、複数のアベイラビリティーゾーンが存在し、それぞれのアベイラビリティゾーンは物理的に離れた位置に存在します。つまり、アベイラビリティゾーンとはデータセンタを指し、リージョンとはそのデータセンタ群が存在する国または地域を指す と考えて問題ないと思います。
例えば東京リージョンには、ap-northeast-1a / ap-northeast-1c / ap-northeast-1d という3つのアベイラビリティゾーンが存在するため、東京近郊に3つのデータセンタが存在するということになります。(具体的な場所については公開されていない)
障害が発生したサービスについて
EC2とはAWSにおける仮想サーバのサービス でAWSにおける最もメジャーなサービスと言っていいと思います。また EBSはEC2のディスク(OSやデータの領域に主に利用される)にあたるサービス で、RDSはリレーショナルデータベースサービスです。
またEC2を利用してサーバを構築する際に、要件に応じて任意のリージョン、アベイラビリティゾーンを選択します。例えば、Webサービスにおいてユーザが日本メインの場合は、Webサービスのユーザとサーバの距離を物理的に近づけレイテンシ(遅延時間)を最小にすることを目的に東京リージョンを選択します。またアベイラビリティゾーンの選択については、可用性(システムが継続して稼働できる能力)を高めるためや負荷分散のために複数のサーバを複数のアベイラビリティゾーンで運用したりします。
つまり?
これらの前提知識から起こった事象について読み解くと、AWSクラウドが運用されている世界各地のロケーションのうち、東京における4つのデータセンタのうち1つのデータセンタに存在する仮想サーバ、ディスク、データベースが使えなくなったということです。
原因について
空調設備の管理システム障害により、EC2サーバのオーバーヒートによってパフォーマンスの劣化や電源の停止によって障害が発生した模様です。
影響を受けたサービス
AWS 東京リージョンで発生した大規模障害についてまとめてみた に本AWSの障害による影響を受けたとみられるサービスの一覧がまとまっています。複数のアベイラビリティゾーンに分散してリソースを配置することで、単一のアベイラビリティゾーンの障害の影響を少なくすることはできますが、単純に考えると障害によりサーバリソースが少なくなることで、リクエストが捌けなくなったり、コストとの兼ね合いから冗長化をしていなかったり、影響を受けたサービスの要因は様々な理由が考えれると思います。
責任の所在について
AWSには 責任共有モデル においてAWSとAWS利用者の責任分担を表明しており、今回はハードウェアが原因の障害であり普通に考えるとAWS側に責任があると考えられます。しかし今回発生した障害は単一のアベイラビリティゾーンにおけるものであり、アーキテクチャの設計やサービスの設定で回避できる問題であったと考えらえるので、AWS利用者側の責任になるのではないかと考えます。
タイムライン
Service Health Dashboard より抜粋。(Google翻訳を利用しています。)
EC2
インスタンスの接続性について
| 日本時間 | 情報 |
|---|---|
| 8/23 13:18 | AP-NORTHEAST-1リージョンの単一のアベイラビリティーゾーンのいくつかのインスタンスに影響する接続の問題を調査しています。 |
| 8/23 13:47 | 一部のインスタンスが損なわれ、一部のEBSボリュームでAP-NORTHEAST-1リージョンの単一のアベイラビリティーゾーン内のパフォーマンスが低下していることを確認できます。一部のEC2 APIでは、エラー率とレイテンシが増加しています。この問題の解決に取り組んでいます。 |
| 8/23 14:27 | 根本原因を特定し、AP-NORTHEAST-1リージョンの単一のアベイラビリティーゾーン内でのインスタンス障害とEBSボリュームのパフォーマンス低下の回復に取り組んでいます。 |
| 8/23 15:40 | AP-NORTHEAST-1リージョンの単一のアベイラビリティーゾーン内で、インスタンスの障害とEBSボリュームのパフォーマンスの低下が回復し始めています。影響を受けるすべてのインスタンスとEBSボリュームの復旧に向けて引き続き取り組みます。 |
| 8/23 17:54 | AP-NORTHEAST-1リージョンの単一のアベイラビリティーゾーン内でのインスタンスの障害やEBSボリュームのパフォーマンスの低下のために、PDTリカバリが進行中です。影響を受けるすべてのインスタンスとEBSボリュームの復旧に向けて引き続き取り組みます。 |
| 8/23 18:39 | パフォーマンスが低下したEC2インスタンスとEBSボリュームの大部分が回復しました。この問題の影響を受ける残りのEC2インスタンスとEBSボリュームの復旧に引き続き取り組みます。この問題は、AP-NORTHEAST-1リージョンの単一のアベイラビリティーゾーンのEC2インスタンスとEBSボリュームに影響します。 |
| 8/23 20:18 | 2019年8月23日 12:36 より、AP-NORTHEAST-1 の単一のアベイラビリティゾーンで、一定の割合の EC2 サーバのオーバーヒートが発生しました。この結果、当該アベイラビリティゾーンの EC2 インスタンス及び EBS ボリュームのパフォーマンスの劣化が発生しました。 このオーバーヒートは、影響を受けたアベイラビリティゾーン中の一部の冗長化された空調設備の管理システム障害が原因です。日本時間 15:21 に冷却装置は復旧し、室温が通常状態に戻り始めました。温度が通常状態戻ったことで、影響を受けたインスタンスの電源が回復しました。日本時間 18:30 より大部分の EC2 インスタンスと EBS ボリュームは回復しました。 我々は残りの EC2 インスタンスと EBS ボリュームの回復に取り組んでいます。少数の EC2 インスタンスと EBS ボリュームが電源が落ちたハードウェア ホスト上に残されています。我々は影響をうけた全ての EC2 インスタンスと EBS ボリュームの回復のための作業を継続しています。 早期回復の為、可能な場合残された影響を受けている EC2 インスタンスと EBS ボリュームのリプレースを推奨します。いくつかの影響をうけた EC2 インスタンスはお客様側での作業が必要になる可能性がある為、 後ほどお客様個別にお知らせすることを予定しています。 |
RDS
インスタンスの接続性について
| 日本時間 | 情報 |
|---|---|
| 8/23 14:22 | AWSでは、現在、東京リージョンの1つのアベイラビリティゾーンで発生している、複数インスタンスに対する接続性の問題について調査を進めております。 |
| 8/23 15:25 | AWSでは、東京リージョンの1つのアベイラビリティゾーンで発生しているインスタンスの接続性の問題について原因を特定し、現在復旧に向けて対応を進めております。 |
| 8/23 16:01 | AWSでは、現在、東京リージョンの1つのアベイラビリティゾーンで発生しているインスタンスの接続性の問題ついて、復旧を開始しております。影響を受けている全てのインスタンスの復旧に向け、対応を継続いたします。 |
| 8/23 18:16 | AWSでは、現在、東京リージョンの1つのアベイラビリティゾーンで接続性の問題が生じている全てのインスタンスの復旧に向け、対応を進めております。 |
| 8/23 22:19 | 日本時間 2019年8月23日 12:36 から 22:05 にかけて、東京リージョンの単一のアベイラビリティゾーンで一部の RDS インスタンスに接続性の問題が発生しました。現在、この問題は解消しており、サービスは正常稼働しております。 |
AWSより詳細の障害報告
東京リージョン (AP-NORTHEAST-1) で発生した Amazon EC2 と Amazon EBS の事象概要 より抜粋。
2019年8月25日(日本時間)初版:
日本時間 2019年8月23日 12:36 より、東京リージョン (AP-NORTHEAST-1) の単一のアベイラビリティゾーンで、一定の割合の EC2 サーバのオーバーヒートが発生しました。この結果、当該アベイラビリティゾーンの EC2 インスタンス及び EBS ボリュームのパフォーマンスの劣化が発生しました。このオーバーヒートは、影響を受けたアベイラビリティゾーン中の一部の冗長化された空調設備の管理システム障害が原因です。日本時間 15:21 に冷却装置は復旧し、室温が通常状態に戻り始めました。室温が通常状態に戻ったことで、影響を受けたインスタンスの電源が回復しました。日本時間 18:30 より大部分の影響を受けた EC2 インスタンスと EBS ボリュームは回復しました。少数の EC2 インスタンスと EBS ボリュームは、電源の喪失と過大な熱量の影響を受けたハードウェアホスト上で動作していました。これらのインスタンスとボリュームの復旧には時間がかかり、一部につきましては基盤のハードウェアの障害によりリタイアが必要でした。
EC2 インスタンスと EBS ボリュームへの影響に加えて、EC2 RunInstances API にも影響が発生しました。日本時間 2019年8月23日 13:21 に、影響の発生したアベイラビリティゾーンでの EC2 インスタンスの起動、および冪等性トークン(複数のインスタンスを起動させる危険なく、インスタンスの起動をリトライする機能)を使用して RunInstance API を東京リージョンで実行した場合に、エラー率の上昇が発生しました。その他の EC2 API や冪等性トークンを使用しない EC2 インスタンスの起動は正常に動作しておりました。この問題は、冪等性トークンを使用する Auto Scaling グループからのインスタンスの新規起動も阻害しました。日本時間 14:51 に、エンジニアは、冪等性トークンと Auto Scaling グループの問題を解決しました。影響の発生したアベイラビリティゾーンでの、新しい EC2 インスタンスの起動は、EC2 コントロールプレーンサブシステムのリストアが完了した日本時間 16:05 まで継続しました。影響の発生した EBS ボリュームのスナップショットの作成も、この期間にエラー率の上昇が発生しました。
今回の事象はデータセンターで使用されるいくつかの冷却システムの制御と最適化に使用されるデータセンター制御システムの障害によって引き起こされました。制御システムは、高可用性を実現するために複数のホストで実行されます。この制御システムには、ファン、冷却装置、温度センサーなどのサードパーティ製デバイスとの通信を可能にするサードパーティ製のコードが含まれていて、直接または組み込みプログラマブルロジックコントローラ(PLC)を介して通信し、実際のデバイスと通信します。今回の事象発生の直前に、データセンター制御システムは、制御ホスト群から制御ホストの 1 つを外す処理を行なっていました。このようなフェイルオーバーの間、新しい制御ホストがデータセンターの最新状況を保持する為に、制御システムは、他の制御システムおよび制御するデータセンター機器 (データセンター全体の冷却装置および温度センサーなど) と情報を交換する必要があります。サードパーティ製の制御システムにおけるロジックのバグにより、この情報交換が制御システムとデータセンターのデバイス間で過度に発生し、最終的には制御システムが応答しなくなりました。AWS のデータセンターは、データセンターの制御システムに障害が発生した場合、制御システムの機能が回復するまで冷却システムが最大冷却モードになるよう設計されています。これはデータセンターのほとんどで正常に機能していましたが、データセンターのごく一部で冷却システムがこの安全な冷却構成に正しく移行できず停止しました。追加の安全策として、AWS のデータセンターオペレータは、通常ではデータセンター制御システムを迂回することで冷却システムを「パージ」モードにすることで故障に際しての熱風を素早く排出します。運用チームは、影響のあるデータセンターのエリアでパージをアクティブにしようとしましたが、これも失敗しました。この時点で、データセンターの影響を受けるエリアの温度が上昇し始め、サーバーが熱くなりすぎ、サーバーの電源が停止し始めました。データセンター制御システムが利用できなかったため、データセンターオペレータはデータセンターの状態と冷却システムの状態に対する可視性が最小限に限定されていました。この状況を改善されるためにはオペレータは影響を受けるすべての機器を手動で調査してリセットし、最大冷却モードにする必要がありました。これらの対応時に一部のエアハンドリングユニットを制御する PLC も応答しないことが見つかりました。これらの PLC はリセットする必要があり、またこの障害によりデフォルトの冷却モードと「パージ」モードが正常に動作していないことが確認できました。これらのコントローラがリセットされると、影響のあったデータセンターのエリアへ冷却が行われ室温が低下し始めました。
現在も、サードパーティのベンダーと協力し、制御システムと応答がなくなった PLC の両面を引き起こしたバグ、並びにバグによる影響の詳細な調査を進めております。平行して、事象の再発を防ぐため、バグを引き起こした制御システムのフェイルオーバーモードを無効にしました。また、もし万が一事象が再現しても対策が取れるよう、オペレータにこの度の事象の検知方法と復旧方法のトレーニングを実施しました。これにより、もし同様の事象が発生しても、お客様への影響が発生する前に、システムのリセットが可能になっております。その他にも、「パージ」モードが PLC を完全にバイパスできるよう、空調システムを制御する方法を変更するよう作業を進めております。これは、最新のデータセンターで使用している方法で、これにより「パージ」モードが PLC が応答がなくなった際でも機能するように出来る、より確実な方法となっています。
この度の事象発生時、異なるアベイラビリティゾーンの EC2 インスタンスや EBS ボリュームへの影響はございませんでした。複数のアベイラビリティゾーンでアプリケーションを稼働させていたお客様は、事象発生中も可用性を確保できている状況でした。アプリケーションで最大の可用性を必要とされるお客様には、この複数アベイラビリティゾーンのアーキテクチャに則ってアプリケーションを稼働させることを引き続き推奨します(お客様にとって高可用性に課題を生じ得る全てのアプリケーションのコンポーネントは、この耐障害性を実現する方法の下で稼働させることを強く推奨します)。
この度の事象により、ご迷惑をおかけしましたことを心よりお詫び申し上げます。AWS サービスがお客様ビジネスに極めて重要である点を理解しております。AWS は完全ではないオペレーションには決して満足することはありません。この度の事象から学ぶために出来得る全てを遂行し、AWS サービスの向上に努めてまいります。
2019年8月28日(日本時間)更新
最初の事象概要で言及した通り、今回のイベントは、東京リージョンの1つのアベイラビリティゾーン(AZ)の一部に影響を与えました。 この影響は当該 AZ の Amazon EC2 および Amazon EBS のリソースに対するものですが、基盤としている EC2 インスタンスが影響を受けた場合には、当該 AZ の他のサービス(RDS、 Redshift、 ElastiCache および Workspaces 等)にも影響がありました。 お客様と今回のイベントの調査をさらに進めたところ、 個別のケースのいくつかで、複数のアベイラビリティゾーンで稼働していたお客様のアプリケーションにも、予期せぬ影響(例えば、 Application Load Balancer を AWS Web Application Firewall やスティッキーセッションと組み合わせてご利用しているお客様の一部で、想定されるより高い割合でリクエストが Internal Server Error を返す)があったことを AWS では確認しております。 AWS では、個別の問題についての詳細な情報を、影響を受けたお客様に直接、共有を行う予定です。
AWSの障害に関する記事まとめ
今回の障害に関するブログ記事を参考になった点とともに以下にまとめます。
- AWS 東京リージョンで発生した大規模障害についてまとめてみた
- 障害報告があったサービス一覧がとてもよくまとまっています
- AWS での AZ 障害に対する冗長化と障害対策のポイント
- AZ名とAZIDの結びつきがAWSアカウントによって異なるなど
- AWS東京リージョン障害に思うこと
- Multi AZでも復旧するのに時間がかかった仮説について
- AWS障害で本当に知っておくべきことと考慮すべきこと
- 今回の障害における責任共有モデルに関する説明
- AWSの大規模障害でMultiAZでも突然ALB(ELB)が特定条件で500エラーを返しはじめたという話
- タイトルの通りです
- AWSのAZ障害で影響を受けた・受けなかったの設計の違い。サーバレス最高!
- AZ障害が様々なサービスの障害に繋がった原因について、サーバレスアーキテクチャで構成することで障害の影響を受けなかったことなど
- AWSのService Health Dashboardに表示される障害対応状況をSlackで受け取る方法
- AWSにおける障害の状況をSlackの通知で受け取るための設定方法
- AWS障害(2019/08/23日本時間13時頃発生)に詫び石(返金)はあるのか?
- SLA によると、今回の障害に関する返金等は無いとの結論です
- AWS障害発生→停止・メンテナンスをアナウンスしたサービスまとめ
- 停止したサービスやアプリのまとめです
- AWS障害が発生した場合に確認するページやサイトまとめ
- AWSで障害が発生した場合に確認するページやサイトについてまとまっています
- 2019/8/23のAWS東京リージョン大規模障害の経過まとめ
- サービス復旧後も影響を受け続けているアカウントへの個別メールの内容など
- 障害から学ぶクラウドの正しい歩き方について考える
- AWSの大規模障害は本当に「クラウドの弱さを露呈した」のか
- 自社のサービスはどれだけのダウンタイムを許容するのかという判断の重要性、カオスエンジニアリングについてなど
- AWSのAZ(アベイラビリティーゾーン)とは?AZ障害が起きたときどうすればよいのか
- ストレージサーバの写真など、データセンタのイメージがつきやすいです
Pseudo Labeling(擬似ラベリング)を使ってみる
Kaggle Instant Gratificationで使われていた Pseudo Labeling(擬似ラベリング)について紹介します。参考: Pseudo Labeling - QDA - [0.969]
Pseudo Labeling(擬似ラベリング)とは?
Pseudo Labelingとは、ラベルのついたデータ(trainデータ)で学習したモデルを利用して、未ラベルのデータ(testデータ)を推論した結果のうち、確度の高いものをラベル付きのデータとして追加して再度モデルを学習させるプロセスを指します。
今回のコンペでは40の特徴量に対して、512行のデータセットを使ってモデルを学習させる必要があり明らかにデータ数が足りないため、擬似ラベリングを行い学習データを増やすことでスコアを伸ばすことができました。
実際のコード
データは こちら から。
ラベルのついたデータ(trainデータ)でモデルを学習
import numpy as np import pandas as pd import os from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis from sklearn.model_selection import StratifiedKFold from sklearn.feature_selection import VarianceThreshold from sklearn.metrics import roc_auc_score train = pd.read_csv('../input/train.csv') test = pd.read_csv('../input/test.csv') cols = [c for c in train.columns if c not in ['id', 'target', 'wheezy-copper-turtle-magic']] oof = np.zeros(len(train)) preds = np.zeros(len(test)) for i in range(512): train2 = train[train['wheezy-copper-turtle-magic']==i] test2 = test[test['wheezy-copper-turtle-magic']==i] idx1 = train2.index idx2 = test2.index train2.reset_index(drop=True, inplace=True) sel = VarianceThreshold(threshold=1.5).fit(train2[cols]) train3 = sel.transform(train2[cols]) test3 = sel.transform(test2[cols]) skf = StratifiedKFold(n_splits=11, random_state=42, shuffle=True) for train_index, test_index in skf.split(train3, train2['target']): clf = QuadraticDiscriminantAnalysis(reg_param=0.5) clf.fit(train3[train_index,:],train2.loc[train_index]['target']) oof[idx1[test_index]] = clf.predict_proba(train3[test_index,:])[:,1] preds[idx2] += clf.predict_proba(test3)[:,1] / skf.n_splits print('QDA scores CV =',round(roc_auc_score(train['target'], oof) ,5))
QDA scores CV = 0.96532
未ラベルのデータ(testデータ)を推論した結果を擬似ラベルとして追加
test['target'] = preds
擬似ラベルのうち、予測確度の高いものを学習データに追加してモデルを学習
oof = np.zeros(len(train)) preds = np.zeros(len(test)) for k in range(512): train2 = train[train['wheezy-copper-turtle-magic']==k] train2p = train2.copy() idx1 = train2.index test2 = test[test['wheezy-copper-turtle-magic']==k] # 擬似ラベルのうち、予測確度の高いものを学習データに追加する test2p = test2[ (test2['target']<=0.01) | (test2['target']>=0.99) ].copy() test2p.loc[ test2p['target']>=0.5, 'target' ] = 1 test2p.loc[ test2p['target']<0.5, 'target' ] = 0 train2p = pd.concat([train2p,test2p],axis=0) train2p.reset_index(drop=True,inplace=True) sel = VarianceThreshold(threshold=1.5).fit(train2p[cols]) train3p = sel.transform(train2p[cols]) train3 = sel.transform(train2[cols]) test3 = sel.transform(test2[cols]) skf = StratifiedKFold(n_splits=11, random_state=42, shuffle=True) for train_index, test_index in skf.split(train3p, train2p['target']): test_index3 = test_index[ test_index<len(train3) ] clf = QuadraticDiscriminantAnalysis(reg_param=0.5) clf.fit(train3p[train_index,:],train2p.loc[train_index]['target']) oof[idx1[test_index3]] = clf.predict_proba(train3[test_index3,:])[:,1] preds[test2.index] += clf.predict_proba(test3)[:,1] / skf.n_splits print('Pseudo Labeled QDA scores CV =',round(roc_auc_score(train['target'], oof) ,5))
Pseudo Labeled QDA scores CV = 0.96769
CVスコアがわずかながら上がっていることが確認できました。
T2T ペア学習・グループ学習の仕組み

今回は、データサイエンスからは少し離れた話です。
私は最近、デザインエンジニアリングファーム Takramのポッドキャスト、Takram Cast をよく聞いています。その中で T2Tの仕組み という回が興味深く面白かったので簡単に紹介しようと思います。
T2Tとは Takram to Takramで、Takramが4月からスタートさせたペア学習・グループ学習の仕組みです。組織の中での効果的な学びを加速させるための取り組みになります。
起源となったのは Googleのg2g(Googler to Googler)だそうです。Podcastの内容について下記にざっくりまとめてみました。
T2Tについて
- T2Tは会社の制度として導入
- T2Tの仕組み
- 1ヶ月ですでに60回、200時間弱の時間がT2Tに費やされた
- これまでどんなテーマがあったか
- 教える側はプロなので、効率的に学べる
- バックオフィスの人も自由に参加できる
- 月5時間は必ずT2Tに取り組むのを義務にしている
- T2TというSlackチャンネルがある
- 投稿フォームの設計で、カレンダーURLを入れてそれをコピペしてスケジュールに追加
- テーマのチャンネルを事前に作る。募集の文章にチャンネルを貼り付ける。それであらかじめ読んでおいてほしいこととか、学習後、オンラインで継続で話が続く
- T2Tの目的はLearning Organization
- 会社側はそれに使える時間を確保するだけ
- 勉強は個人でできるけど、分からないところなどを気軽に周りに聞ける仕組みがない
- 一度やったのは、ブログを書いたり、nortionに書いたりしてたが面倒だったので広まらなかった
- よって省エネ設計が重要
- 越境というテーマがあるが、知らない分野を社内のスペシャリストに気軽に聞けるようになればいいなという思いで始めた
- メルカリではM2M、heyではH2Hとして流行りつつある
その他
- Book purchaseという仕組みもあり、本がほぼ買い放題
- 毎月10冊ぐらい買ってる
- こっちは個人学習
- Google re:Work というGoogleの働き方がまとまったサイトがある
- 教えることは自分にも勉強になる
- セルフアップグレード制度があり下記をサポート
- カンファレンスに出る
- 外部のレクチャーを聞く
- オンラインスクール
- 英会話
- 新しいハードウェアを触れるように購入をサポートをするR4Dという制度を入れている。
以上、ポッドキャストの内容をまとめてみました。 興味があればご自身でも聞いてみてください。
How to Win a Data Science Competition: Learn from Top Kagglers Week2 講義メモ
全体概要
- How to Win a Data Science Competition: Learn from Top Kagglers の講義メモ
- 機械学習の基礎がある前提で、Kaggleで上位に喰い込むための知識、スキルを身につけるための講義
- 解説者がロシア人?のため、若干英語に癖があるが字幕があるので問題無し
- Week2は、EDA, バリデーション、データリークについて解説
1週目のメモは下記になります。
EDAとは
- データを見て、慣れるプロセスのこと
- タスクの理解それを解くために何が与えられているのかを理解する
- データを理解することで新しい特徴量を作成するための仮説を立てることができるようになる
- データをロードしてすぐにモデルにデータを食わせると一見いいスコアが得られるかもしれないが、まずは必ずEDAをするべき。そうしないとTOPにはなれない
- TOP層は注意深いEDAを行なってデータからインサイトを得ている
可視化
- EDAの一つのツールとして可視化がある
- 可視化をすることでパターンを読み取ることができる
Building intuition about the data
- ドメイン知識を得る
- ググってカラムの意味を調べる
- 直感的に正しいかどうかを調べる
- 例えばageのカラムに330才などが無いか
- クリック数がインプレッションよりおお多くなってないか
- 間違っている場合は、is_incorrectフラグを立てると良い
- trainとtestがどうやって生成されたかを理解する
- ランダムにサンプリング
- 特定のクラスをオーバーサンプリングなど
- 正しいバリデーションをするために理解が必要
- trainデータがtestデータと異なっていると、trainデータの一部はtestデータをrepresentiveしないのでバリデーションセットとして使うことはできない
- 違いがあればtrainとtestの可視化をしてみるとよくわかる
anonymized dataとは
- 例えばドキュメントの分類問題で、テキストがエンコード化されたものなど
- カラム名が匿名化されていることがある
- カラムの意味を特定できることもあるができないこともある
- できない場合はカラムがnumericなのかcategoricalなのかは判定できるはず
- df.dtyoes
- df.info()
- x.value_counts()
- x.isnull()
Visualizations
- ヒストグラム
- 特徴をbinにしてbinごとに何個あるかカウントする

- ヒストグラムはmisleadingを引き起こすこともあるので注意する. 例えば下記はほぼ0の値に偏っているように見えるが、logをとると別の分布がみられる


- これから言えることは、一つのプロットから結論を出さないことが重要
- 特徴をbinにしてbinごとに何個あるかカウントする
trainとtestのdistributionが同じかチェックするのにscatter plotを使う。下記の例でいうと、右上の方がtrainデータとマッチしていないので良くない。

Exploring individual features
- plt.scatter(x1, x2)
- pd.scatter_matrix(df)
- df.corr()
- plt.matshow( ... )
- df.mean().sort_values().plot(style=' .')
Duplicated and constance feature
- constant feature は取り除くべき
- 例えば、yearカラムがあって、配布されたデータが1年分で2018しかない場合は取り除くべき。
- data.nunique(axis=1 == 1
- trainデータでは、constant, testデータで別の値があっても学習時にはconstantな値のなので、取り除く
- duplicated featureは取り除く
- ただ学習時の邪魔になるので取り除く
- 下記のようにぱっと見違うようだが、実はduplicatedな特徴もあるのでその場合はlabel encodingして確認する

- duplicated rowsは取り除く


Validation
- validationの目的は、testデータでもっとも精度の良いモデルを選択するため
- kaggleではtrainとtestデータが与えられるが、trainデータをtrainとvalidationに分けてモデルの精度を検証する
モデルのcomplexityのちょうどいいところを探すイメージ

validation types
- Holdout
- シンプルにtrainとvalidationに分割する手法
- データが十分にある場合か異なる分割をしても同じようなスコアが出る場合は Holdoutは有効
- K-fold
- Holdoutを別の分割でk回行う手法
- k回行ったvalidationのスコアを平均したものを結果とする
- データが十分に無い場合か異なる分割をするとスコアが全然異なる場合は K-foldが有効
- Leave-one-out
- K-foldのKがtrainのサンプル数のパターン
- データがとても少量でモデルを学習させるのに十分な場合に有効
- Holdout
K-foldとHoldoutはシャッフルされたデータで利用するのが普通
- あるクラスのサンプルが少ない場合、random splitは失敗することがある
stratification(層化)
- ターゲットのクラス割合を保って分割する
- データが少ない場合や、ターゲットのクラス割合がアンバランスな場合、マルチクラス分類に有効
Data splitting strategy
- 下記のような時系列データの場合、左のケースはvalidationスコアとtestスコアが剥離する。右のケースの場合はvalidationスコアとtestスコアが近いので、右のように分割するといい
- trainとtestの分割方法を見極めて、それと同じようにtrainとvalidationを分割する
splitting data into train and validation
- random
- rowが独立している場合。例えばローンを返すかどうかを予測するケースで一行が1人に該当するような場合
- timewise
- 時系列順で最初の方をtrainデータ、後半の方をtestデータとする
- 先週の売り上げや先月の売り上げなどの特徴量が思いつく
- id
- idとはユーザやショップなどを一意に識別できるもの
- 例えば、新しいユーザに音楽のリコメンデーションをするタスクの場合、trainとtestのユーザは完全に異なる。こういったケースでは、その音楽をこれまで何回聞いたかなどの特徴量は意味をなさない
- combined
- ここよくわからなかった
- 一番重要なのは、コンペのオーガナイザによって分割されたtrainとtestと同じ分割の方法でtrainとvalidationの分割もすること
- random
Problem occurring during validation
- trainとvalidationのsplitによってスコアや最適なパラメータに大きな差が出てしまう問題
- 2月の売り上げを予測するタスクで1月をvalidationに使うようなパターン。1月は休みが多く、売り上げは大きいためMSEは2月より大きくなってしまう。だからといってモデルの精度が悪いと言えない
- この問題が起こってしまう時は下記のようなパターン
- データが少ない場合
- データがdiverseでinconsistantな場合
- この問題に対して下記の方法が考えられる
- K-Foldの平均スコアを使う
- あるfoldでモデルのチューニングを行い、別のfoldでスコアを評価する
- LBスコアとvalidationスコアに剥離が出てしまう/LBスコアとvalidationスコアの相関性が無い
- K-Fold内で大きく異なるスコアが出ているから
- public leaderboardのデータが少ないから
- この場合はvalidationを信じる
- trainとtestのdistributionが異なるから
- 例えば、trainは女性の身長、testが男性の身長データの場合、モデルのpredictionは女性の身長の平均値あたりになりvalidationではスコアがスコアがいいが、submitすると悪くなる。こういう時は、trainの平均とtestの平均の差分をsbmitデータに追加してやれば良い。
- 下記のようなdistributionの場合、validationの割合をtestの割合と同じようにしてやれば良い

- trainとvalidationのsplitによってスコアや最適なパラメータに大きな差が出てしまう問題
最後のsubmission二つのうち一つはpublic leaderboardがもっともいいもの、もう一つはvalidationスコアがもっともいいものを選ぶといい
Basic data leaks
- leakageとは予期しない情報がデータにあり、それによって非現実的な予測ができてしまうこと
コンペでleakが起こるとタスクを解くために費やした時間が無駄になってしまう
Leaks in time series
- 例えば、明後日の株価データを使って明日の株価を予測することはもちろんできないが、間違った time splitがあることできてしまうことがある
- 時系列データで、train, public, privateの分割をチェックして、一つでも on timeではないものがある場合、leakを見つけることができる?
- on timeでも未来の情報を含んでいる
- test setのrowにアクセスできるため、例えば未来のユーザヒストリーなどを取得できる
- 時系列データでleakを無くすためには、特徴量のないtest setにする。例えばIDだけとか
- 参加者は過去から特徴量を自分で作る
- Unexpected information
- 例えば、猫と犬の画像を識別するコンペで、猫の画像の方が先に撮られている場合、それが分かってしまうメタデータが残っているとleakになってしまう
- IDからleakする場合。基本はIDはランダムに割り当てられるのでモデルに組み込んでも意味はないが、何かのハッシュになっていることがあるので、使えるかどうかをチェックする価値はある
- 一般的なケースでは、データはtarget variableによってシャッフルされるが、そうでないこともあり。例えば、rowが近いものは同じラベルを持っているコンペが存在した
Leaderboard probing and example of rare data leaks
- Leaderboard probingには二種類ある
- public leaderboardからground truth(真値)を得る
- submissionの特定の行を変更してスコアを見てground truthを計算する。詳細についてはリンクを参照
- idが同じものが同じtarget値をもつ場合を考える
- submissionを全て0にして提出してスコアが改善した場合、publicにおけるground truthは0で、privateについても同様である submissionを全て0にして提出してスコアが悪くなった場合、publicにおけるground truthは1で、privateについても同様である
- C : constant prediction
- N : real number of row
- N1 : the number of rows with target
- L : LB score given by that constant prediction
- メトリックがloglossのbinary classificationタスクを考える。test setは10000 row、全て0.3で提出するとpublic scoreは1.01だった。この場合のtest setにおけるpublic部分のtarget variableの平均値は何になるか。下記の数式を使って計算すると 0.7712 になる。
- public leaderboardからground truth(真値)を得る

How to Win a Data Science Competition: Learn from Top Kagglers Week1 講義メモ
全体概要
- 機械学習の基礎がある前提で、Kaggleで上位に喰い込むための知識、スキルを身につけるための講義
- 解説者がロシア人?のため、若干英語に癖があるが字幕があるので問題無し
- Week1は、データの前処理についての解説がメイン
Week1
データ分析コンペ
Kaggle以外にもたくさんある。例えば下記。
- Kaggle
- DrivenData
- CrowdAnalityx
- CodaLab
- DataScienceChallenge.new
- Datascience.net
- SIngle-cometition sites like KDD, VizDoom
参加前にルールはちゃんと確認しよう。
現実とでコンペの違い
現実だと下記などを考慮する必要がある。
- 課題設定
- 評価指標の決定
- 推論速度
- データ収集
- モデルの複雑性の考慮
コンペだとターゲットである評価指標がよければ、推論速度もモデルが複雑であっても、メモリをたくさん消費しようともOK!
Recap of main ML algorithms
- linear Model
- Vompal Wabbit Library
- 大きいデータセット向けに設計されている
- Vompal Wabbit Library
- tree based model
- k-NN
- neural net
No free lunch theorem(ノーフリーランチ定理)を意識する。全ての問題に対して高性能なアルゴリズムは存在しないということ
Feature preprocessing and generation
Features
- numeric
- categorical
- ordinal
- datetime
- coodinate
前処理と特徴生成のパイプラインはモデルのタイプに依存する
Feature preprocessing for numeric feature
- スケーリング
- スケーリングが必要なモデルとそうでないモデルがある
- tree base modelはfeatureのスケールによらない
- non tree based model、kNN, linear model, neural netはスケールによってモデルの精度が変わってしまう
- sklearn.preprocessing.MinMaxScaler
- 0 ~ 1 の間にスケーリングする
- スケーリングが必要なモデルとそうでないモデルがある
- 外れ値
- linear modelは学習に大きく影響してしまう
- 99%外の外れ値を除去などする(winsorization)
- rank
- 外れ値対策のため
- rank([-100, 0, 1e-5]) == ([0 ,1 ,2])
- scipy.stats.rankdata
- rankする前に trainとtestをconcatする
- log transform
- 特にNNに良い
- 大きな値を平均値に近づけることができるため
- その他
- 異なるpreprocessingされた特徴量をconcatしたデータフレーム でtrainする
- 異なるpreprocessingされた特徴量をそれぞれでtrainしたモデルをmixする
Feature generation for numeric feature
Feature generationとはデータやタスクに対する理解、知識を使って新しい特徴量を作成すること
- 掛け算や割り算、feature interactionはlinear model以外(Gradient desicion tree)にも効いてくる
- モデルがロバストになる
- ツリーの数を減らすことができる
- fractional partを追加
categorical, ordinal feature
- ordinal featureとは titanicでいう Pclass(チケットのクラス)
- order categorical feature
- 順序がある特徴量
- 例:幼稚園、小学校、中学校、高校、大学など
label encoding
- カテゴリ値を数値に置き換える
- ツリーベースのモデルはlabel encodingは使える
- non tree modelは別の方法でencodeする必要がある
- S, C Qをlabel encodingする場合
- alphabetical 2 ,1 3
- sklearn.preprocessing.LabelEncoder
- Order of apperance 1, 2, 3
- Pandas.factorize
- alphabetical 2 ,1 3
frequency encoding
- This will preserve some information about value distributiion.
encoding = titanic.groupby('Embarked').size() encoding = encoding / len(titanic) titanic['enc'] = titanic.Embarled.map(encoding)
[S , C. Q] = [0.5, 0.3, 0.2]
- value frequencyがtarget valueに相関があれば効果的
- もしマルチカテゴリで同じfrequencyのものがあった場合、frequency encodingをしても意味が無い
- rankdataを使う https://docs.scipy.org/doc/scipy-0.16.0/reference/generated/scipy.stats.rankdata.html
- どうすればいい??
- rankdataを使う https://docs.scipy.org/doc/scipy-0.16.0/reference/generated/scipy.stats.rankdata.html
>>> from scipy.stats import rankdata >>> rankdata([0, 2, 3, 2]) array([ 1. , 2.5, 4. , 2.5]) >>> rankdata([0, 2, 3, 2], method='min') array([ 1., 2., 4., 2.]) >>> rankdata([0, 2, 3, 2], method='max') array([ 1., 3., 4., 3.]) >>> rankdata([0, 2, 3, 2], method='dense') array([ 1., 2., 3., 2.]) >>> rankdata([0, 2, 3, 2], method='ordinal') array([ 1., 2., 4., 3.])
one hot encoding
- categorical featureをカテゴリ数分、列を増やしてバイナリで表現するencoding
- non tree based modelにきく
oと1なのでスケール不要
sklearn.preprocessing.OneHotEncoder
- Note that if you care for a fewer important numeric features, and hundreds of binary features are used by one-hot encoding, it could become difficult for tree-methods they use first ones efficiently.
- categorical featureがたくさんの unique valueを持っている場合、たくさんのカラムを追加することになる
- この場合に sparce matricesを理解しておく必要がある
- non zero valueのみをメモリに格納することで、メモリの節約になる
- sparce matricesはcategorical feature , text dataに使えることが多い
- XGBoost, LightGBMなどは sparce matricesをそのまま使える
- この場合に sparce matricesを理解しておく必要がある
date and time
- 周期性
- week ,month, season, year, second, minute, hour
- 繰り返しのパターンをつかむのに良い
- time since
- 独立性のある時間特徴量
- 1970/1/1 0:00:00からの経過時間
- 依存性のある時間特徴量
- 特定の出来事からの経過時間 例:セールからの時間
- 独立性のある時間特徴量
- difference between dates
- last_purchase_date - last_call_date = date_diff
datetimeから新しい特徴量を作成したら、numeric featureやcategorical featureを得るが、それらは以前述べた方法で適切な前処理が必要
coodinates
ある不動産価格の予測をする場合、
- ある建物までの距離 例:病院まで距離、学校までの距離
- 地価の高いエリアとの距離
- 重要ポイントクラスターの中心地との距離
- エリア周辺のオブジェクトの集計統計
- 不動産価格の平均
- 決定木を使う場合は、座標を回転させると精度が上がることがある
- とりあえず45, 22.5°回転させるといい
欠損値
- missing valueには情報が隠れている
- hidden NaNs
- ヒストグラムを書いて 0 ~ 1の間に値が分散しているのに -1がある場合
- 欠損の埋め方
- -999や-1など
- 関係のないカテゴリに置き換える
- linear model, neural networkには良くない
- 平均や中央値など
- linear model, neural networkには良い
- reconstructする
- isnullフラグをつける
- -999や-1など
- テストセットにあって、学習セットにないようなカテゴリがある場合は、frequency encodingを使うなど、どちらでも使える特徴量を追加するのもあり
- 欠損値はkaggleの主催者によって置き換えられていることがあるので、ヒストグラムを使って確認する
Feature extraction from text and images
- Bag of words
- 出てきた単語分、次元を増やして単語カウントをする
 ]
] - Bag of word後は、kNN, linear model, neural net などはpost processingが必要
- TF(1レコード内の合計が1になるように正規化)

- IDF(多くの文書に出てくる単語の影響を小さく、あまり出てこない単語の影響を大きくする)

N-grams(N個の連続した単語からなる配列)

text preprocessing
- Lowercase
- 小文字に変換する Veryとveryが別の単語にならないように
- lemmatizatiin and stemming
- lemmatizatiinはsawはsaw or see
- stemmingはsawはs
- stopwords
- モデルに不要な単語のリスト
- Lowercase
- 出てきた単語分、次元を増やして単語カウントをする
Word2vec, CNN
- Word2vec, Glove, FastText
- 単語を数百次元で表す
- 文章をベクトル化したい場合、単語ベクトルの平均や合計を用いるか、Doc2vecを用いる
- 学習に時間がかかるので、pre trainedモデルをインターネットで探すのが良い
- 例えばwikipediaを学習したものなどがある
- 学習の前に text preprocessingをやってから
- Doc2vec
- 単語ではなく、文章をベクトル化したい場合に用いる
BoWとWord2vecの比較
- BoW
- とても大きいベクトルになる
- ベクトルの各要素が単語として分かる
- Word2vec
- 比較的小さいベクトルになる
- ベクトルの要素はある限られた場合にのみ理解できる
- 似たような単語が似たようなembeddingsになる
- BoW
CNN
- Word2vecと似たように、CNNは画像から圧縮された表現を得ることができる
初 Kaggle Microsoft Malware Predictionに参加しました

はじめに
- Microsoft Malware Predictionが終了
- 自分にとって初Kaggleだったが最後まで飽きることなく続けることができた
- 結果は(Pub:265位, Pri:673位)と奮いませんでしたが、学びが多かったのと身に着けるべき知識等がわかったので満足
- 次は CareerCon 2019 - Help Navigate Robots に参加予定
- ただのメモなのでご留意ください
自分の解法
ベースライン
- LightGBM. Baseline Model Using Sparse Matrix をベースモデルとして利用
- シンプルなコードながらシングルモデルでスコアも高かったため
- Train, Testの偏りを無くしたり、observationが少ないものをdropしたり、最後にOne Hot EncodingでSparceな行列を作ってLightGBMに突っ込んでいたりと、とても勉強になった
- このコードをforkして一行一行コードを確認して、どう改善していけばいいかアイディアを練った
- kaggleは一からコードを書くものなのか、それとも良さげなKernelをForkして自分なりに改変していくのかどっちがメジャーなんでしょう?
特徴量エンジニアリング
- とにかく自分が今まで経験した中でもデータが重かったので、取り回しだけでも大変だった
- 不要なカラム(skewed, missing等)の削除
- 似たような特徴量の削除
- Feature Importanceが高い特徴量の Interaction Feature なども追加したりした
- 公開カーネルを参考にして特徴量の追加 ms_malware_starteR
- Rだったので最初は無視していたが、参考にして特徴量を追加したら + 0.001ぐらい上がった
- こういう magic feature的なものはどう見つけるのか知りたい(センスや経験だと思うが)
- Target Mean Encodingを試したが、Pubilcのスコアはむしろ下がった(やり方が悪いのかも)
- 中盤くらいでもう何をしたらいいかアイディアが出なくなって手が動かなくなった
- これは経験と知識が全く足りないので、たくさんコンペ等に参加してノウハウをためていきたい
- 特徴量エンジニアリングはどのコンペでも使えるものと、ドメイン知識等が必要なものがあると思うので、とりあえず前者はマスターしたい
- バージョン系の特徴量にもっと注意を払うべきだった
ハイパーパラメータ チューニング
- 知識がなかったのでLightGBMのドキュメントを見ながら色々試してみただけ
- 自動最適化ツールが試せなかったので、次までにoptunaのチュートリアルでもいいのでやる
アンサンブル
- LightGBMと公開Kernelに自分で作成した特徴量を突っ込んだもののblendをしたりした
- 次はStackingも試したい
その他
- Kernelやdiscussionを読んで、分からなかった単語はググって Quizletという単語アプリに追加していって復習したりした
- 基本Kernelでやっていたが、メモリがどうしても足りない時があったので、GCEのプリエンティブ インスタンスを利用した
- Kernelのコードをコピって、GCEのファイルにペースとして python train.pyとかやっていたのでもっとスマートな方法を考えたい
- 試行錯誤した流れをメモ帳でもいいので書いておくようにする
- 同じ試行錯誤を何度かやっていた気がする。。。
- publicスコアの低めのkernelでも示唆を含んだものもあるので注意
- 今回のコンペはLightGBMばかりだったが、XGBoostがなかったのはなぜ?
- 一度XGBを使ったら学習が全く終わらなかったがなぜ?
上位入賞者の解法(随時追加予定)
6位 CPMP
本コンペの課題について
- train, public, privateの分布が明らかに違っている点
特徴量エンジニアリング
- バージョンに関する特徴量については integer encoding、sub featuresへの分解
- さらに LongYin によって提案されていたcounting features を使用
- target mean encoding、外部データからの日付を使用した、オリジナルデータまたは外部データなどに基づくさまざまな lag feature など探索をした
- これらはほとんど何もワークしていないようだった
Data processing
- データ(作成されたものも含む)は、train と test 間の分布差を減らすために処理
- オリジナルのデータを使用すると、Adversarial Validation で AUC 0.98を超える値が出ていたが、処理したデータでは AUC 0.7以下に抑えることができた
- 処train と test で頻度が非常に異なる値をマージ
- EngineVersionで例が以下の図
- 一つ目ぼ元のデータの train の頻度を赤で、test の頻度を青で示す
- 2番目の図は、処理後の値の頻度を示す


Cross Validation
- 私たちは層化5分割交差検証から始めましたが、これがあまり信頼できなかった
- 最終的に、5分割交差検証とさまざまな時間分割ベースのローカル validation を使用
- 3つすべての検証スキームとLBを使用して潜在的な feature をテストし、それらすべてを改善したもののみを受け入れた
- このテストに合格したものはほとんど何もない(以下で説明する1つの feature を除いて)
A magic feature
- magic featureは、同じEngineVersionにおけるMax AvSigVersion と AvSigVersionとの差
- この feature だけでプライベートLBスコアが0.02増加
Models
- LightGBM: pubLB 0.698
- Keras: pubLB 0.696
ML_Bearさん
特徴量エンジニアリング
- LBが完全時系列分断されている可能性があることを指摘しているKernelがあったため、特にバージョン系の特徴量の取扱に気をつけた
- AvSigVersionは日付に変換して日付として処理を行った
- ここは自分もやっていたがもう少し深掘りすべきだった
- 特徴量エンジニアリングは全部参考になるので勉強する
モデル
- LightGBMは特徴量180個くらい
- こんなに多いのは驚いた
その他
- データが重かったのでモデルを組んだり特徴量のテストをする時はデータを1/4程度にサンプリングして使ってました
- 自分はずっと全データでやっていたがサンプリングもありだなと思った
- とにかくデータが重かったので特徴量作成はBigQueryを主としていました。
- 自分もAthenaなりBigQueryなりを使えたらFeature Engineeringはだいぶ楽になりそう